消息队列
点击阅读更多查看文章内容
消息队列引入


什么是消息队列

Kafka
使用场景:
- 日志信息(离线信息)
- Metrics数据 (程序状态采集)
- 用户行为(搜索、点赞、评论、收藏)
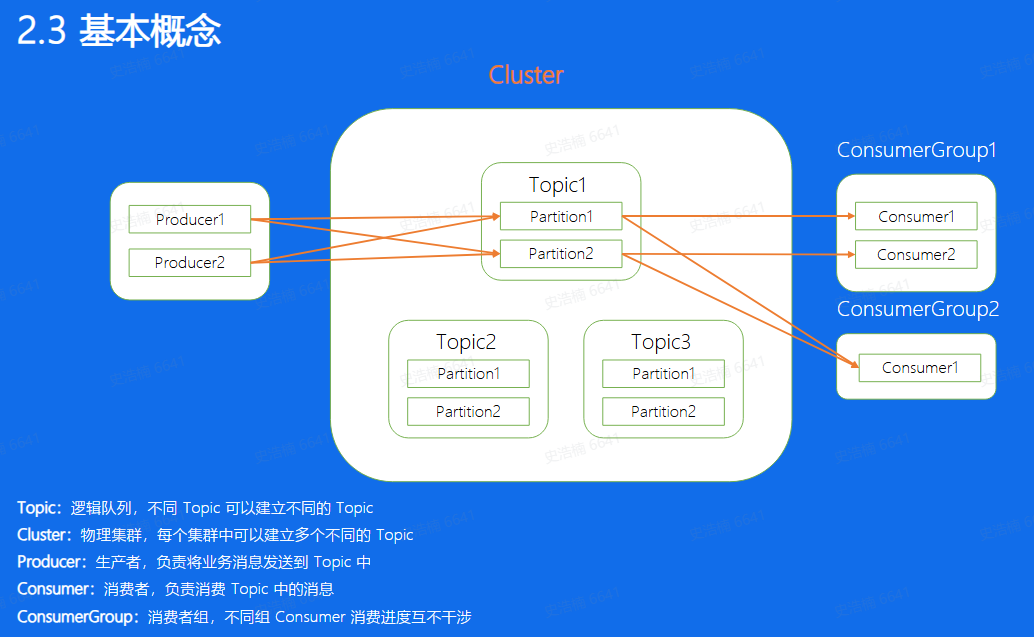
- 一个业务场景对应一个topic,该业务的所有数据都存储在这个topic中
- 一个topic可以分为不同的partition,多个partition可以并发处理提高单个topic的吞吐量

- 对于每一个Partition来说,每条消息都有一 个唯一的Offset, 消息在partition内的相对位置信息,并且严格递增
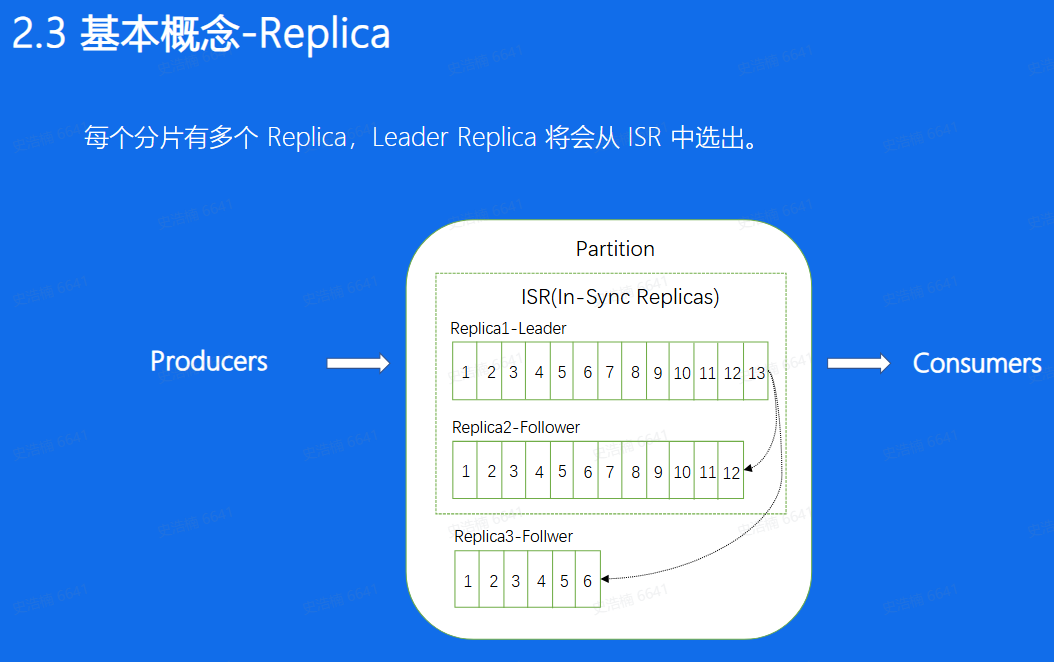
Replica:分片的副本,分布在不同的机器上,可用来容灾,Leader对外服务, Follower异步 去拉取leader的数据进行一个同步, 如果leader挂掉了,可以将Follower提升成leader再对外进行服务
ISR:意思是同步中的副本,对于Follower来说, 始终和leader是有一 定差距的, 但当这个差距比较小的时候,我们就可以将这个follower副本加入到ISR中,不在ISR中的副本是不允许提升成Leader的
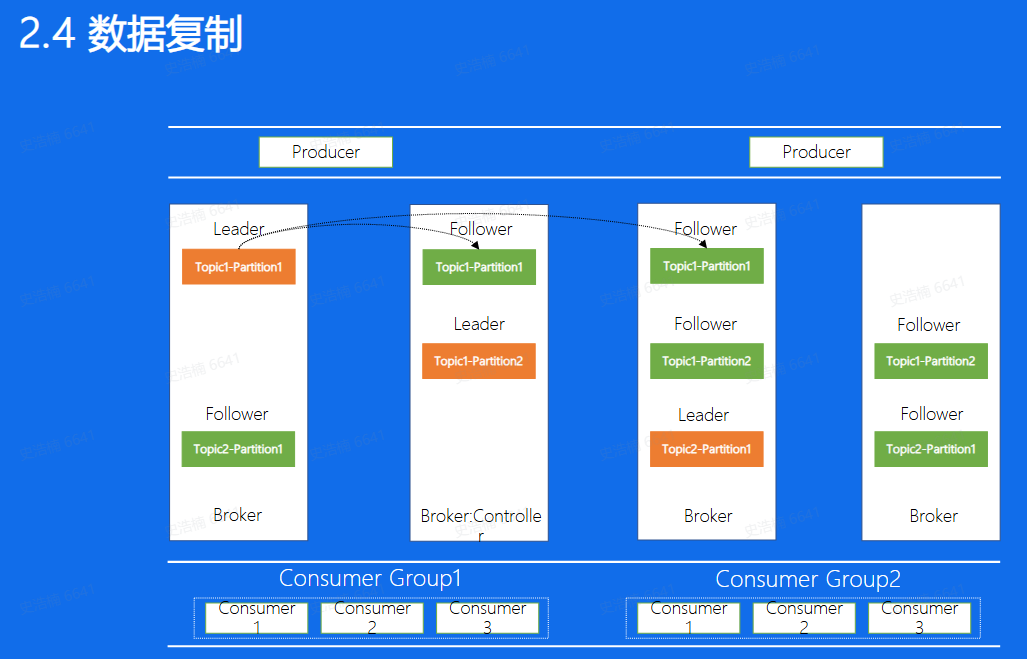
- 上面这幅图代表着Kafka中副本的分布图。图中Broker代表每一个Kafka的节点, 所有的Broker节点最终组成了一个集群。整个图表示,图中整个集群,包含了4个Broker机器节点,集群有两个Topic, 分别是Topic1和Topic2, Topic1有两个分片,Topic2有1个分片, 每个分片都是三副本的状态。这里中间有一个Broker同时也扮演 了Controller的角色,Controller是整 个集群的大脑,负责对副本和Broker进行分配
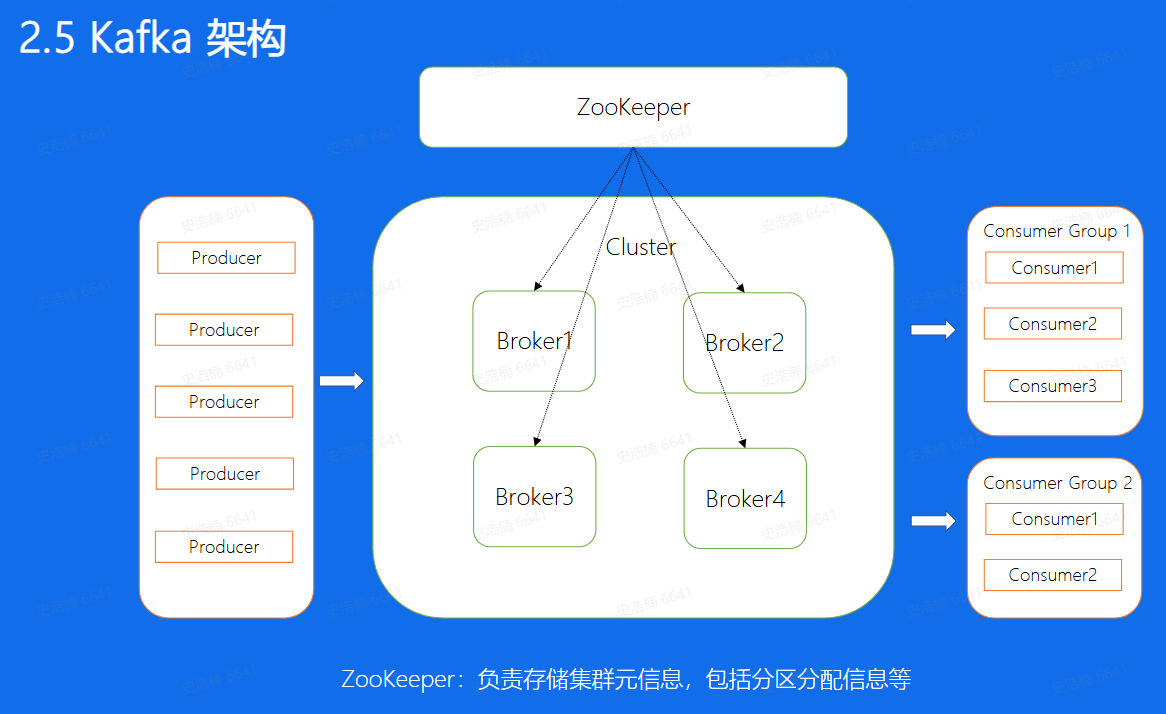
- ZooKeeper与Controller相配合,Controller计算好的方案都会放到这个地方
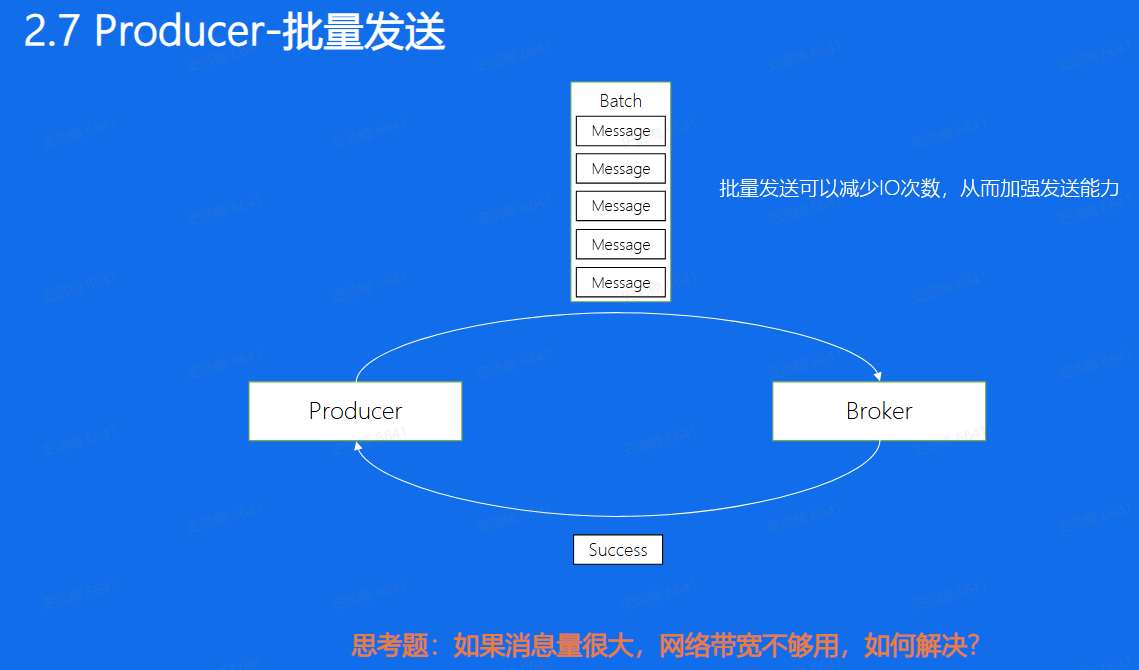
批量发送
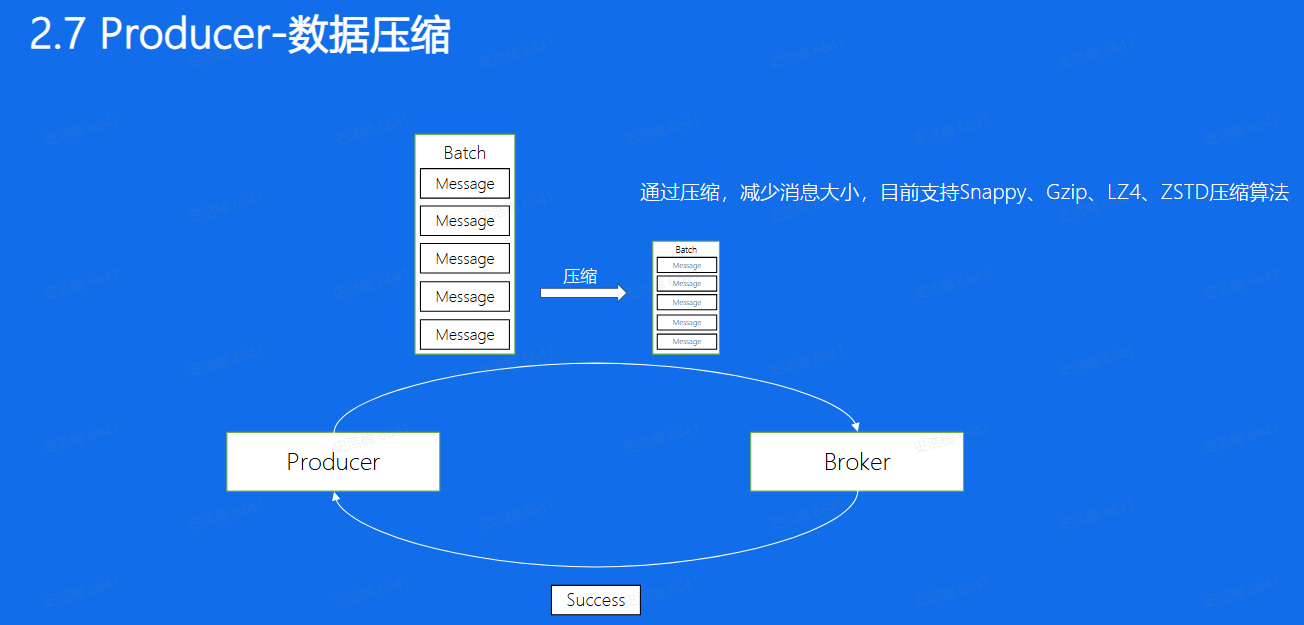
数据压缩
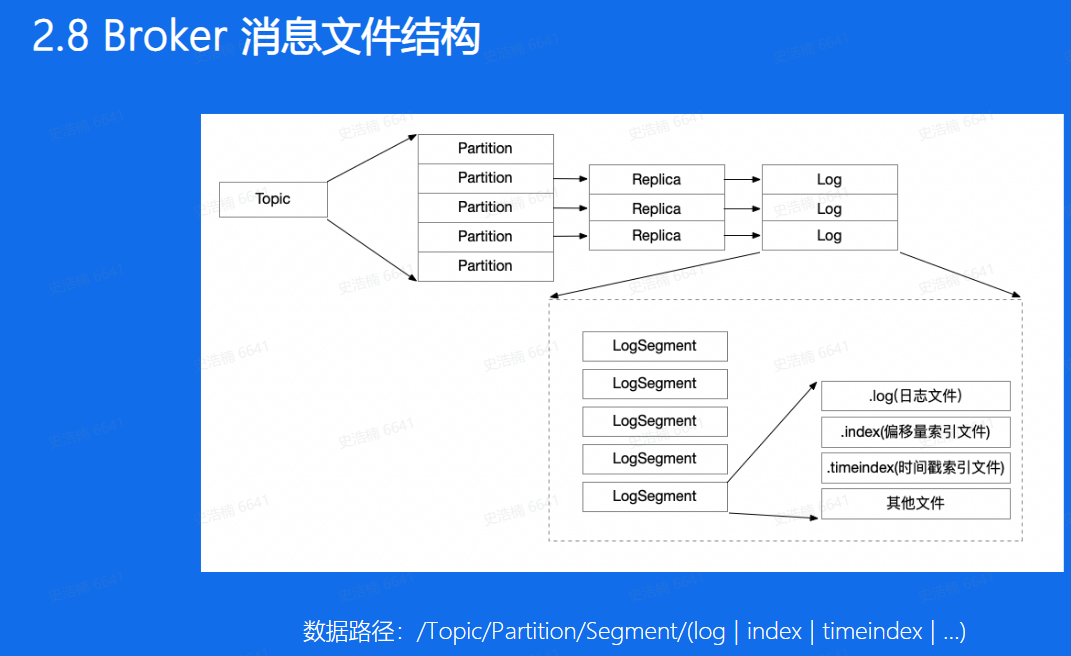
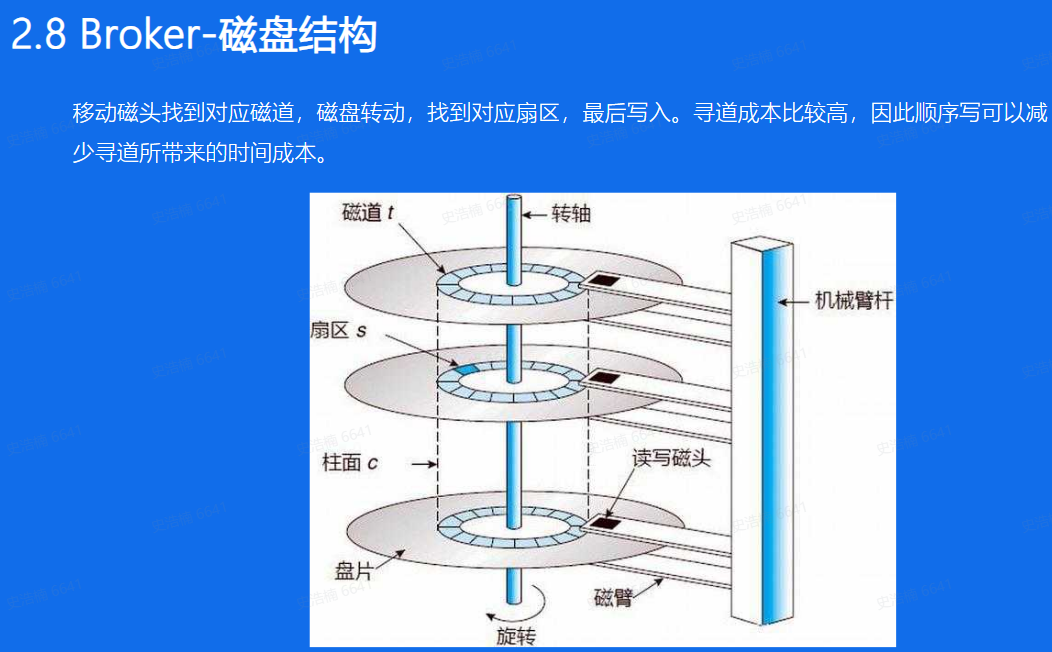
Broker存储数据

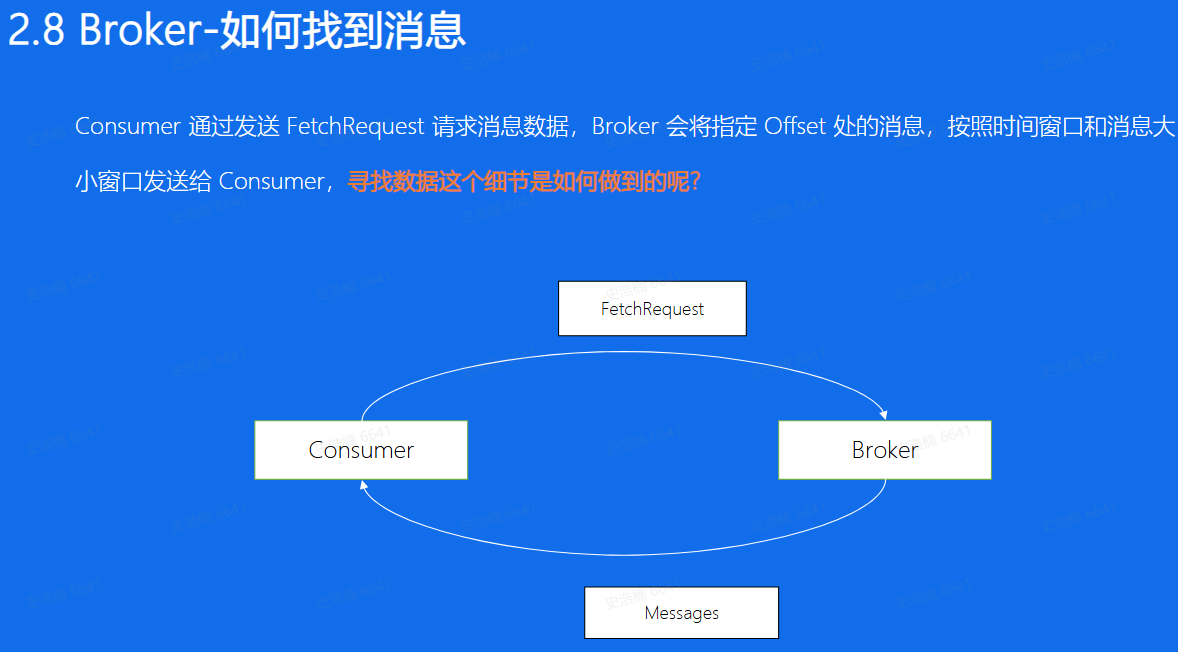
- 查找数据



消息消费
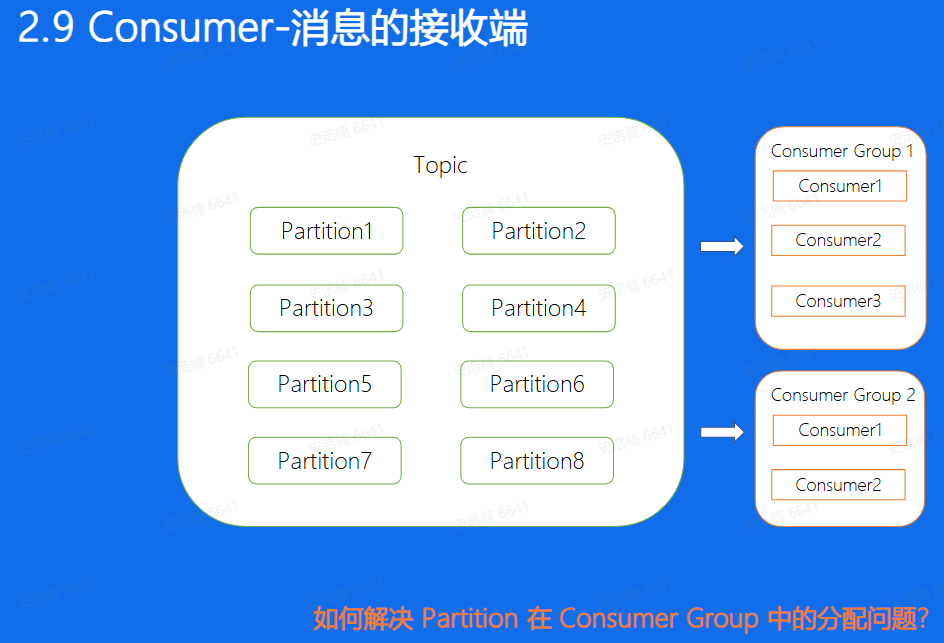
对于一个Consumer Group来说,多个分片可以并发的消费,这样可以大大提高消费的效率,但需要解决的问题是,Consumer和Partition的分配问题, 也就是对于每一个Partition来讲, 该由哪一个Consumer来消费的问题。对于这个问题,我们一般有两种解决方法,手动分配和自动分配。
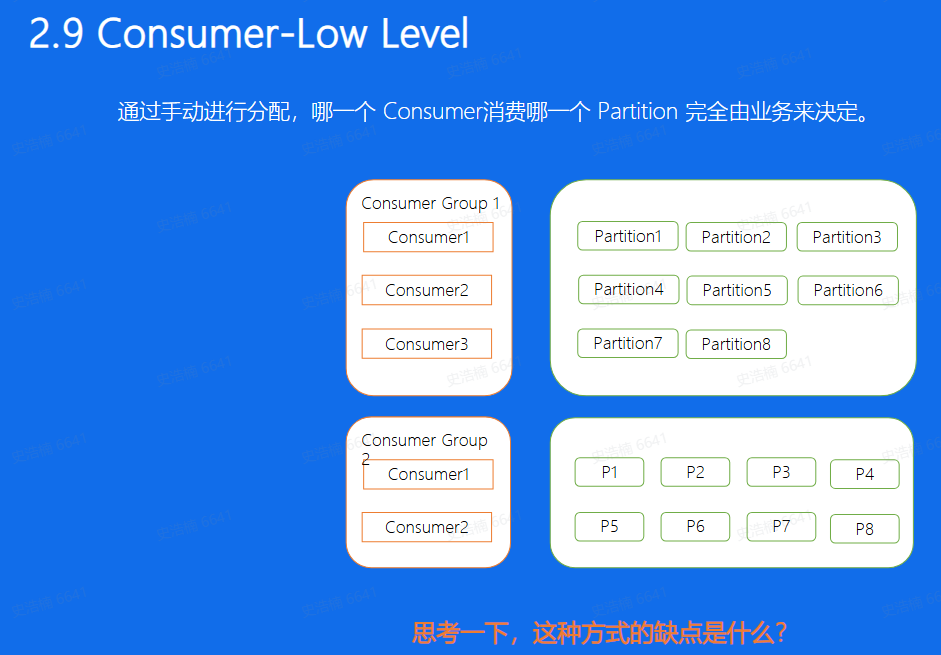
手动分配,也就是Kafka中所说的Low Level消费方式进行消费,这种分配方式的一个好处就是 启动比较快,因为对于每一个Consumer来说, 启动的时候就已经知道了自己应该去消费哪个消费方式,就好比图中的Consumer Group1来说,Consumer1去消费Partition1,2,3 Consumer2, 去消费456,Consumer3去消费78。 这些Consumer再启动的时候就已经知道分配方案了,但这样这种方式的缺点又是什么呢,想象一下,如果我们的Consumer3挂掉了,我们的7,8分片是不是就停止消费了。又或者,如果我们新增了一台Consumer4, 那是不是又需要停掉整个集群,重新修改配置再上线,保证Consumer4也可以消费数据,其实上面两个问题,有时候对于线上业务来说是致命的。
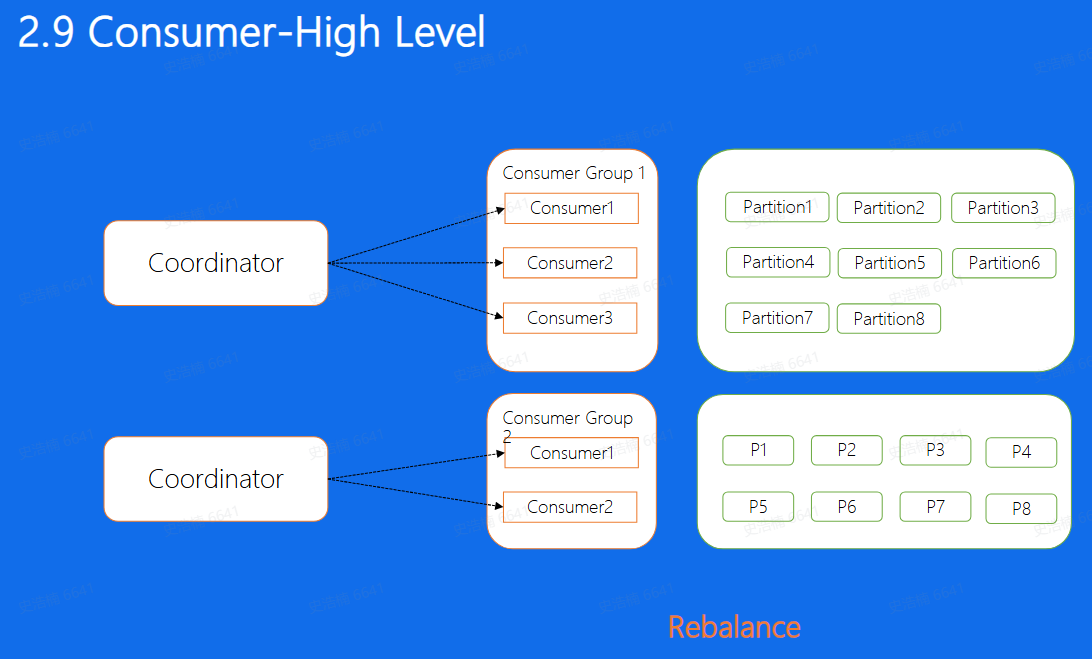
- 所以Kafka也提供了自动分配的方式,这里也叫做High Level的消费方式,简单的来说,就是在我们的Broker集群中, 对于不同的Consumer Group来讲,都会选取一台Broker当做Coordinator, 而Coordinator的作用就是 帮助Consumer Group进行分片的分配,也叫做分片的rebalance,使用这种方式,如果ConsumerGroup中有发生宕机,或者有新的Consumer加入,整个partition和Consumer都会 重新进行分配来达到一个稳定的消费状态


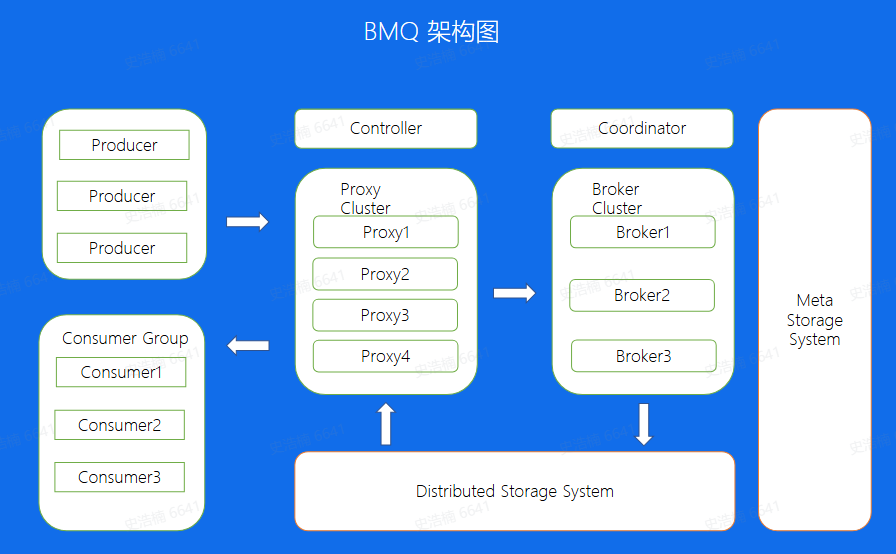
BMQ
兼容Kafka协议,存算分离,云原生消息队列
- 运维操作对比


通过前面的介绍,我们知道了,同一个副本是由多个segment组成,我们来看看BMQ对于单个文件写入的机制是怎么样的,首先客户端写入前会选择一定数量的DataNode, 这个数量是副本数,然后将个文件写入到这 三个节点上,切换到下一个segment之后,又会重新选择三个节点进行写入。这样-来, 对于单个副本的所有segment来讲,会随机的分配到分布式文件系统的整个集群中
- BMQ文件结构
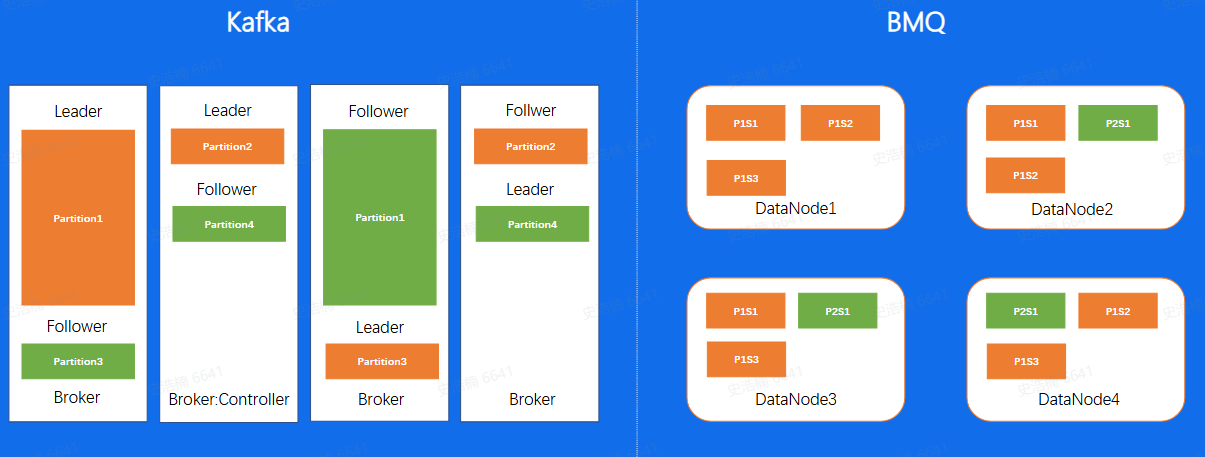
对于Kafka分片数据的写入,是通过先在Leader上面写好文件,然后同步到ollower上,所以对于同一个副本的所有Segment都在同一 台机器 上面。就会存在之前我们所说到的单分片过大导致负载不均衡的问题,但在BMQ集群中,因为对于单个副本来讲,是随机分配到不同的节点上面的,因此不会存在Kafka的负载不均问题
- Broker-Partition 状态机
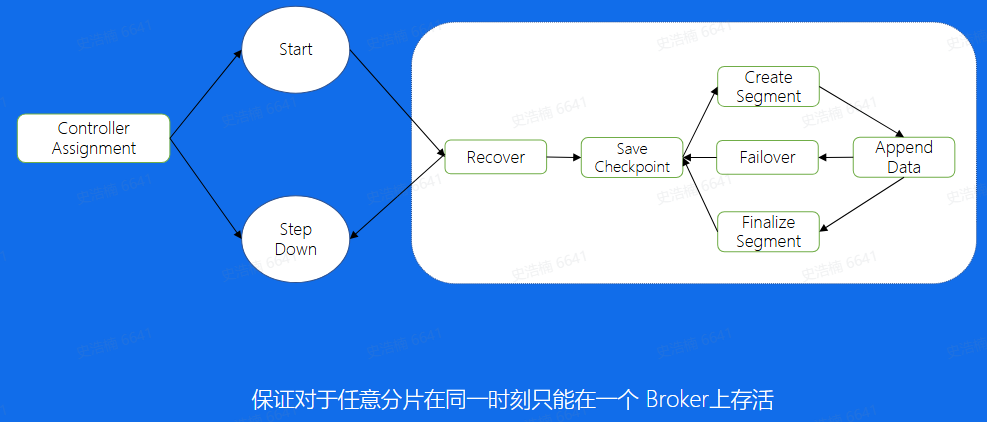
其实对于写入的逻辑来说,我们还有一个状态机的机制, 用来保证不会出现同一个分片在两个Broker 上同时启动的情况,另外也能够保证一个分片的正常运行。 首先,Cortoller做好分片的分配之后, 如果在该Broker分配到了Broker,首先会start这个分片, 然后进入Recover状态,这个状态主要有两个目的获取分片写入权利,也就是说,对于hdfs来讲, 只会允许我一个分片进行写入, 只有拿到这个权利的分片我才能写入,第二-个目的是如果 上次分片是异常中断的,没有进行save checkpoint,这里会重新进行- -次savecheckpoint, 然后就进入了正常的写流程状态,创建文件,写入数据,到一定大小之后又开始建立新的文件进行写入。

RocketMQ
使用场景

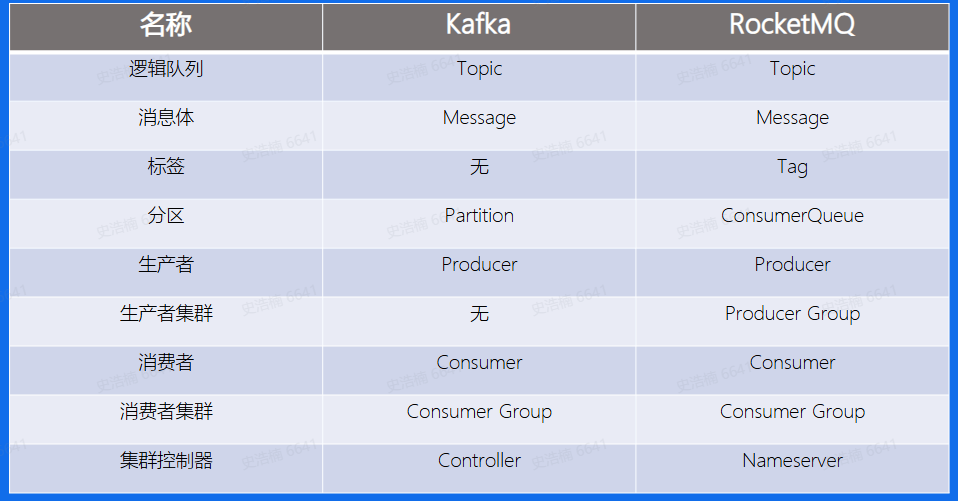
基本概念:
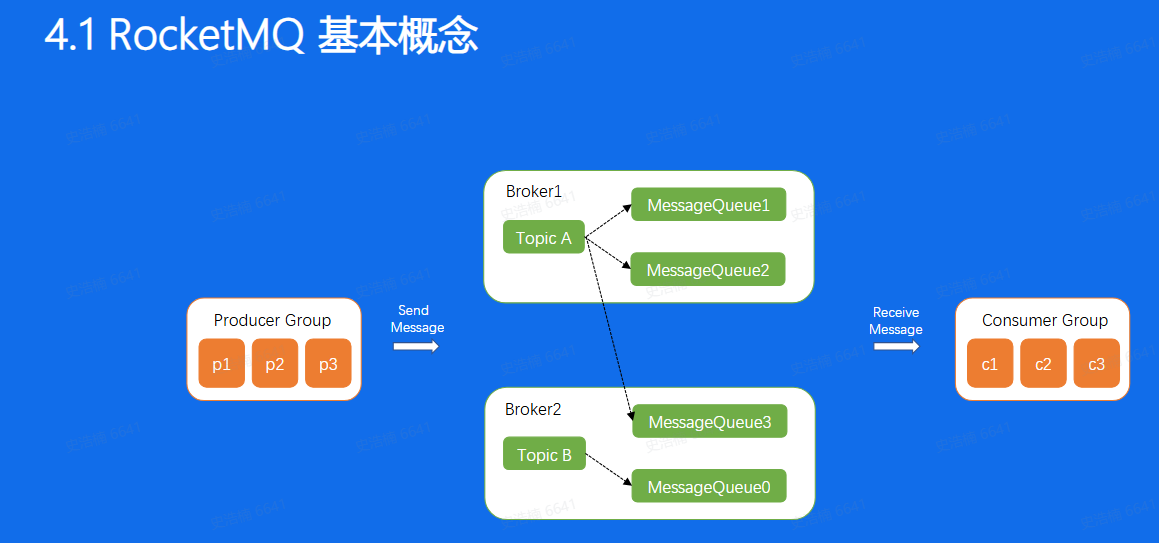
可以看到Producer, Consumer, Broker这三 个部分,Kafka和RocketMQ是一 样的, 而Kafka中的Partition概念在这里叫做ConsumerQueue,
架构:
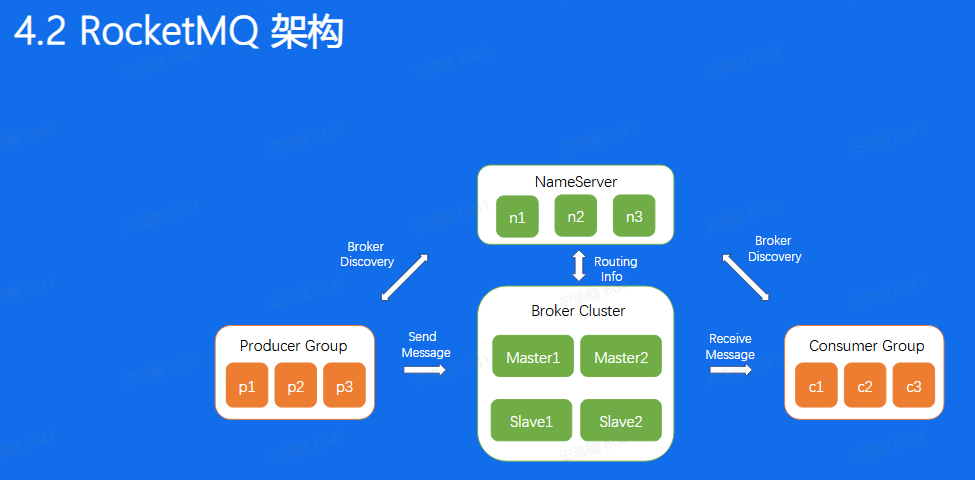
先说数据流也是通过Producer发送给Broker集群,再由Consumer进行消费
Broker节点有Master和Slave的概念
NameServer为集群提供轻量级服务发现和路由
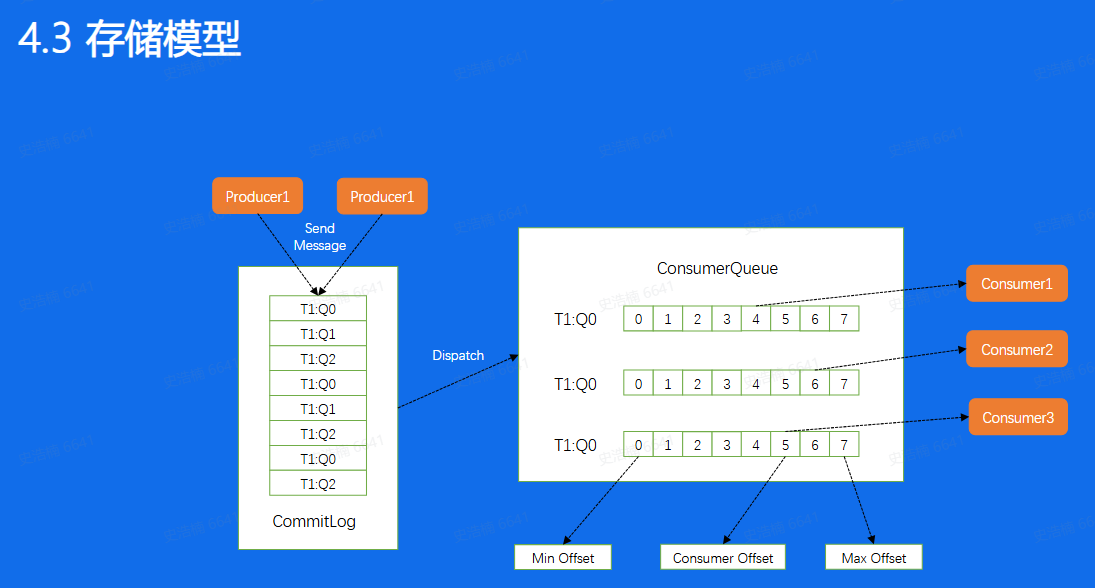
接下来我们来看看RocketMQ消息的存储模型,对于一个Broker来说所有的消 息的会append到一个CommitLog 上面,然后按照不同的Queue,重新Dispatch到不同的Consumer中, 这样Consumer就可以按照Queue进行拉取消费,但需要注意的是,这里的ConsumerQueue所存储的并不是真实的数据,真实的数据其实只存在CommitLog中, 这里存的仅仅是这个Queue所有消息在CommitLog.上面的位置,相当于是这个Queue的一个密集索引
事务