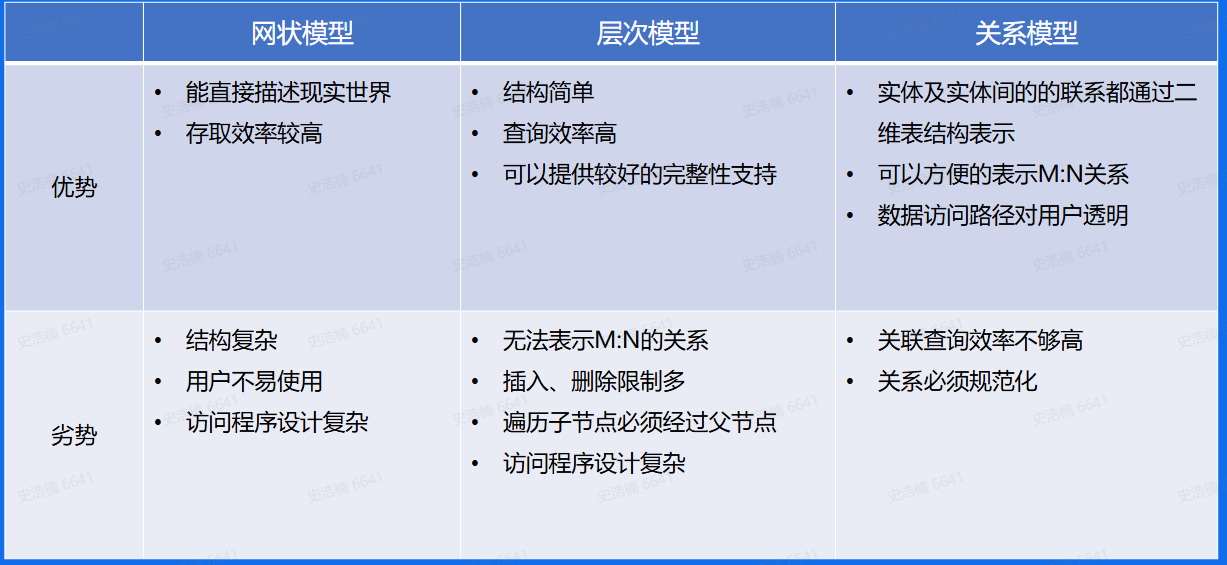
存储与数据库
点击阅读更多查看文章内容
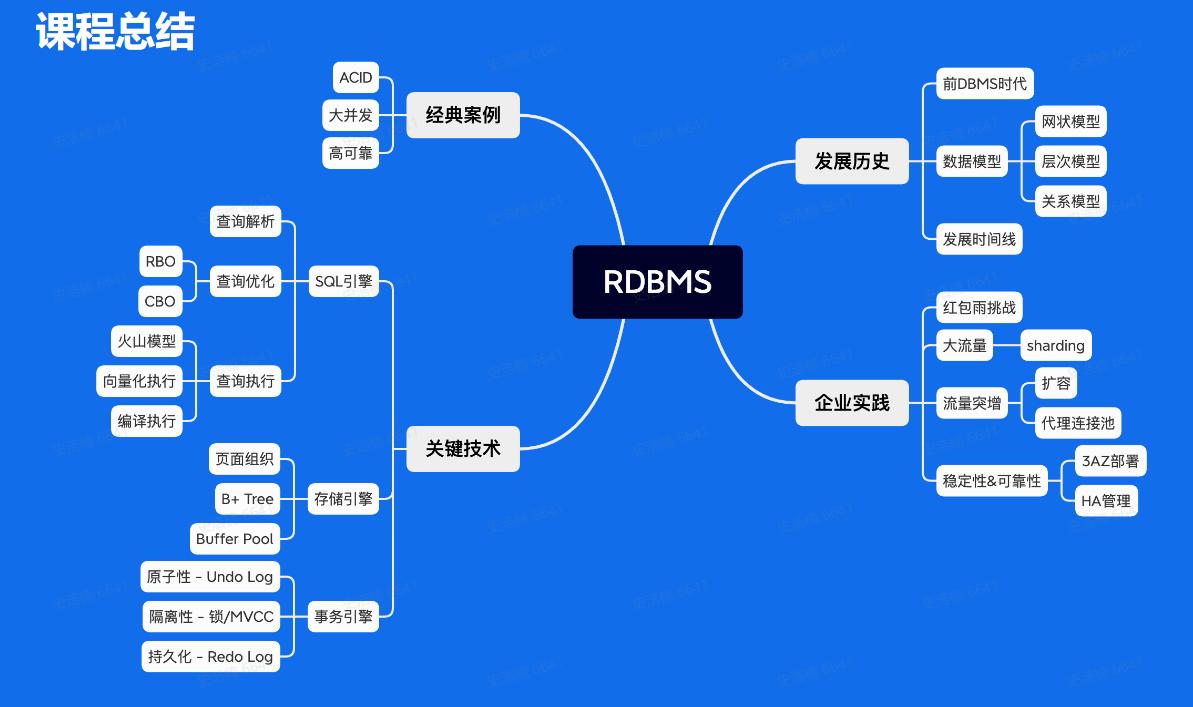
RDBMS
经典案例
事务ACID

原子性:
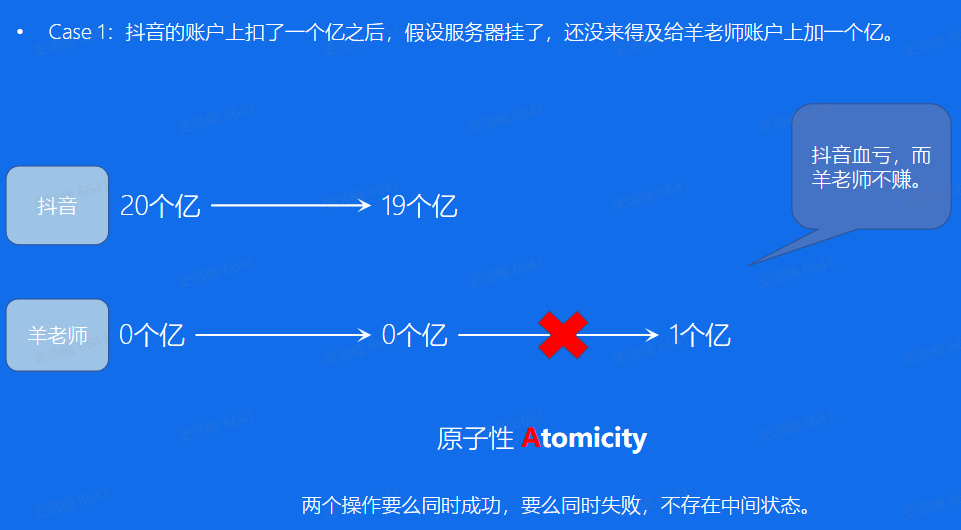
一致性:(强调状态的合法性)

隔离性:
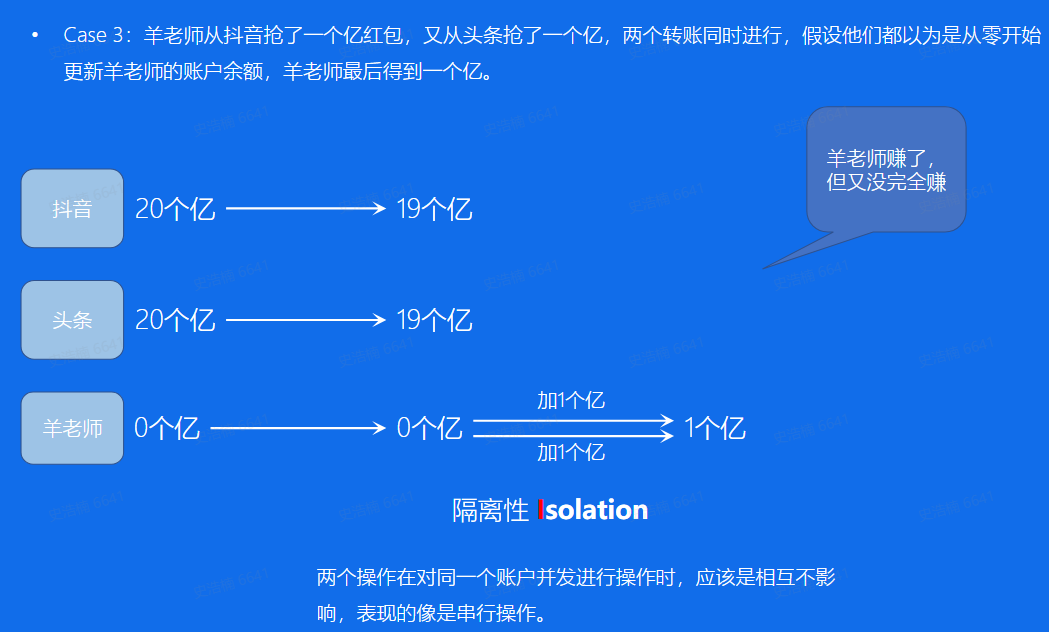
持久性:

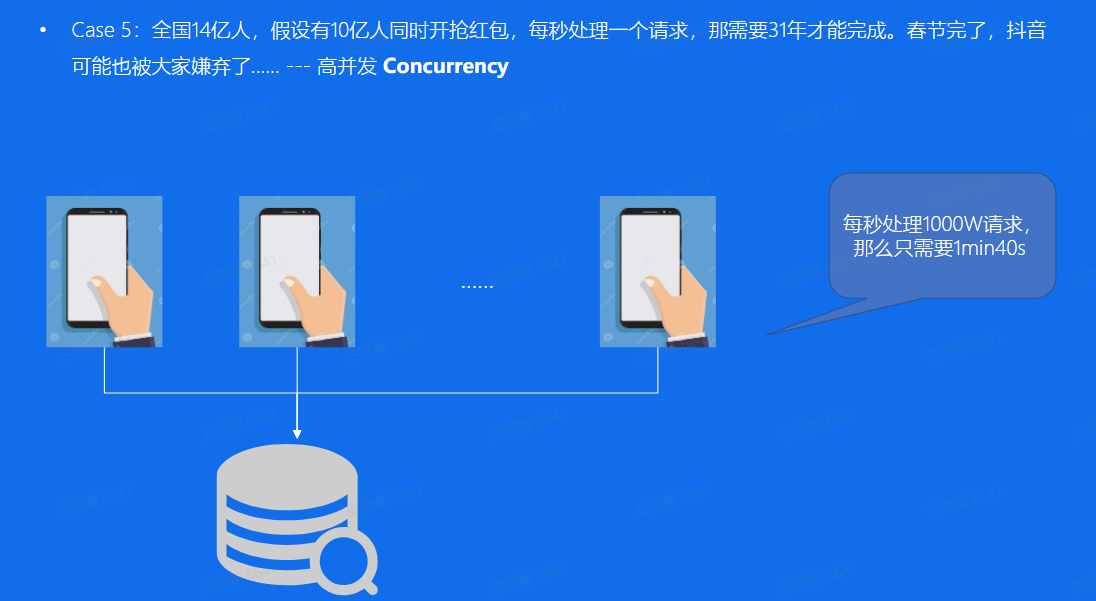
高并发
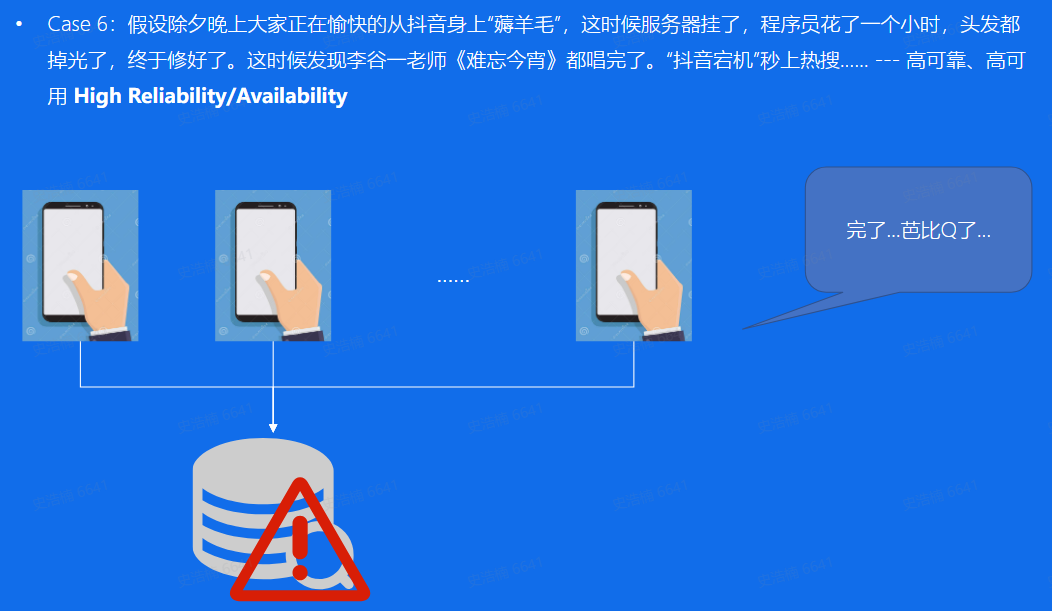
高可靠
数据模型
关键技术
一条SQL的一生
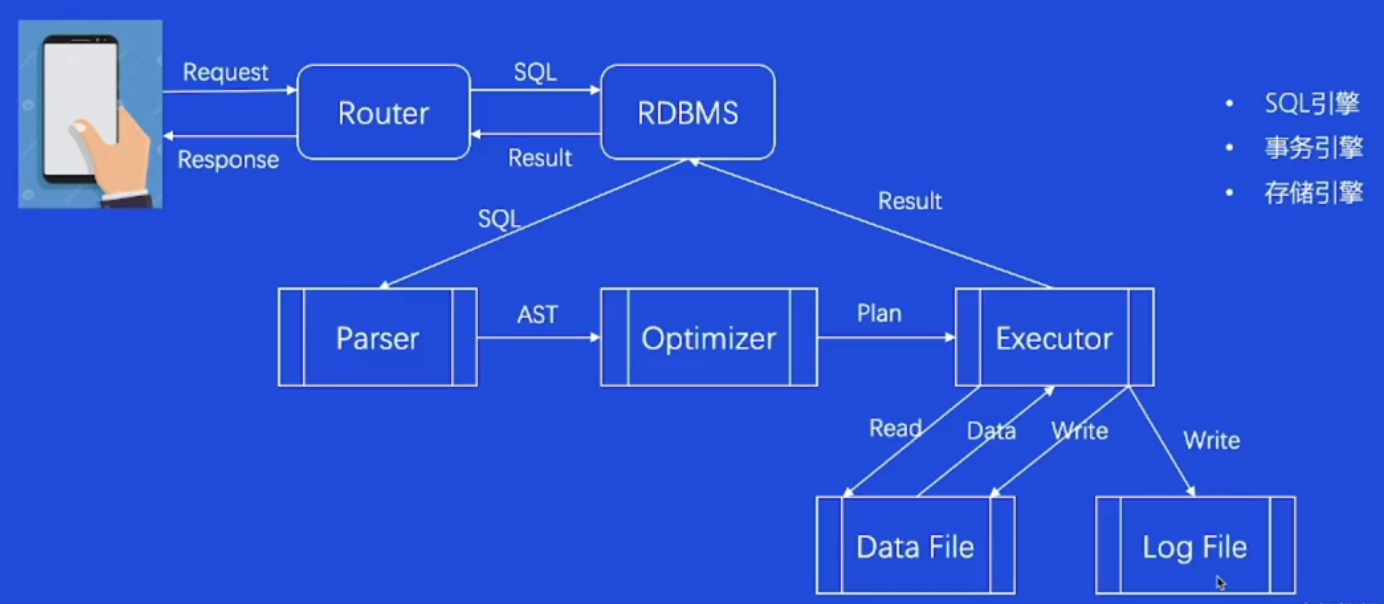
SQL引擎
Parser 解析器
所有的代码在执行之前,都存在一个解析编译的过程, 差异点无非在于是静态解析编译还是动态的。SQL语言也类似,在SQL查询执行前的第一步就是查询解析
- 词法分析:将一条SQL语句对应的字符串分割为一个个token, 这些token可以简单分类。
- 语法分析:把词法分析的结果转为语法树。根据token序列匹配不同的语法规则,比如这里匹配的是update语法规则,类似的还有insert、 delete、 select. create、 drop等等语法规则。根据语法规则匹配SQL语句中的关键字,最终输出一个结构化的数据结构。
- 语义分析:对语法树中的信息进行合法性校验。

Optimizer 优化器
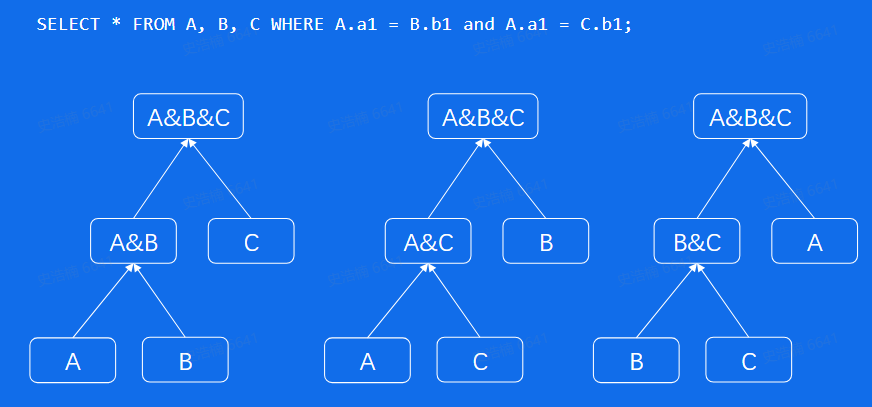
为什么需要优化器?
表连接有多种方式:
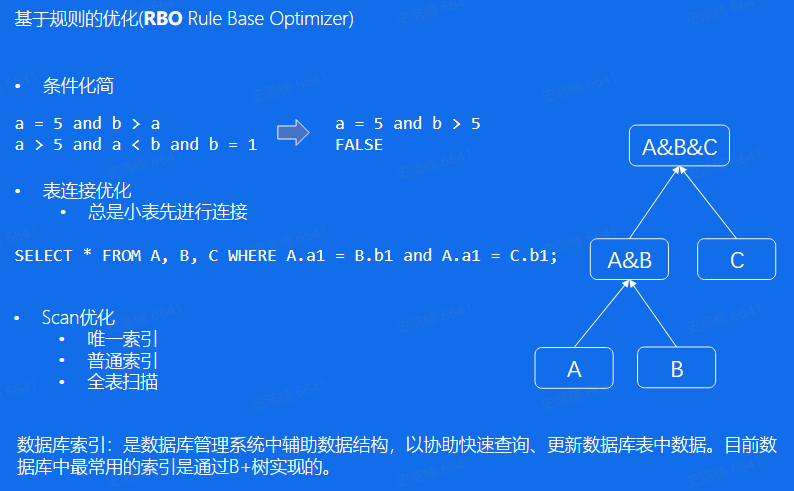
基于规则的优化:
基于代价的优化:(通常考虑整体的代价)
Executor 执行器
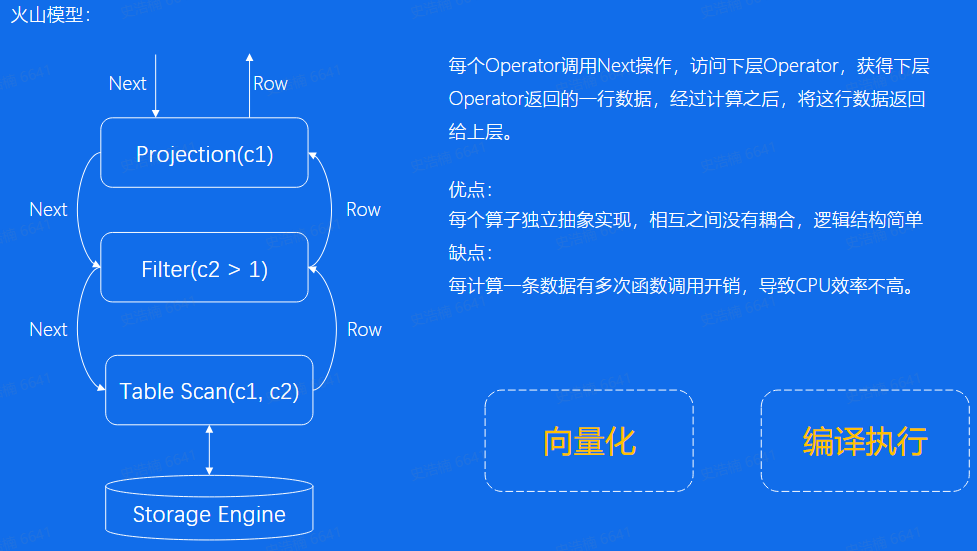
火山模型:逐层向下调用,逐层向上返回
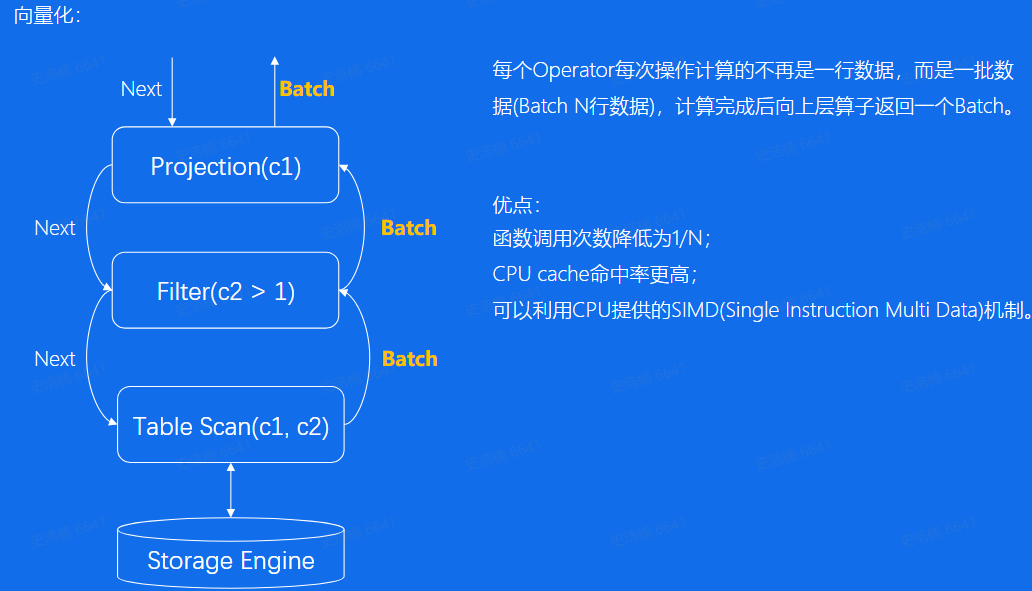
向量化模型:每次计算一批数据
编译执行模型:

存储引擎
InnoDB
内存中进行数据缓存
磁盘中存储:数据元信息(ibdata1)、用户真实数据(xxx.ibd)、日志信息(xxx.ibu、ib_logfileN)、临时表(xxx.ibt)
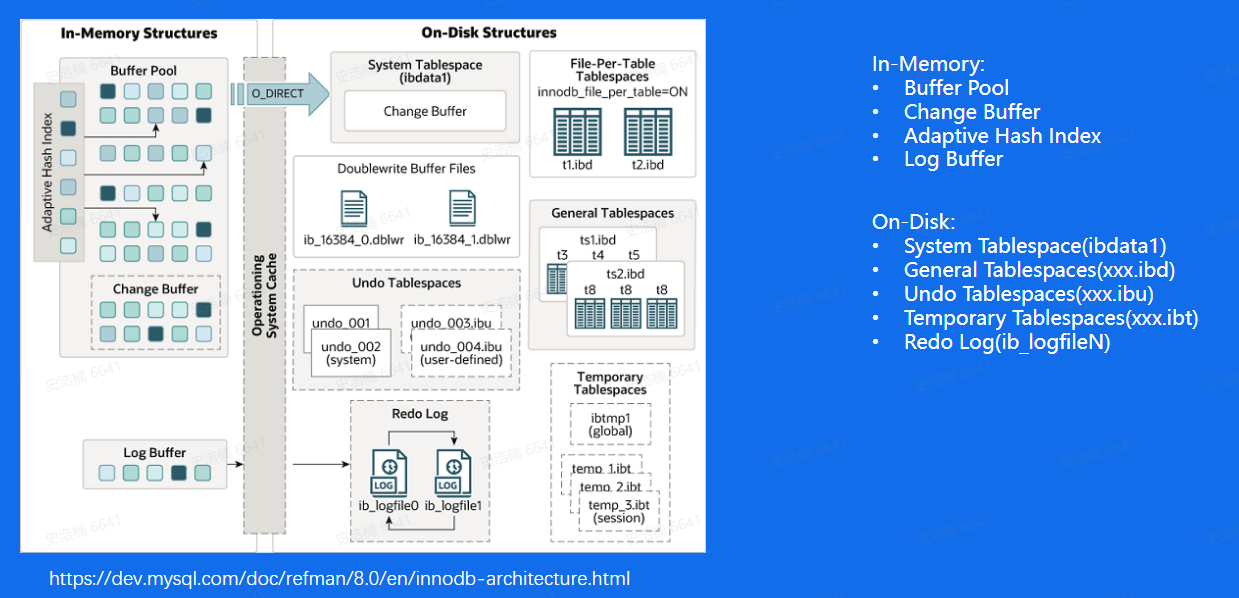
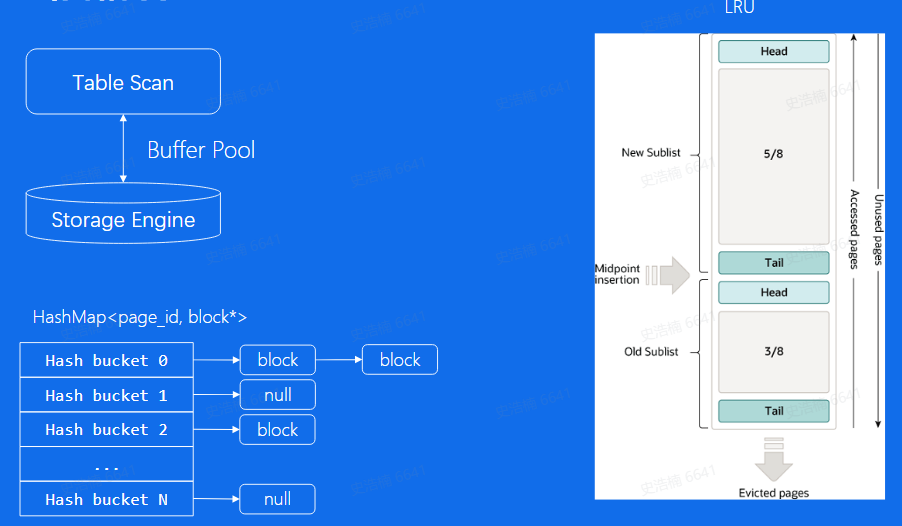
Buffer Pool
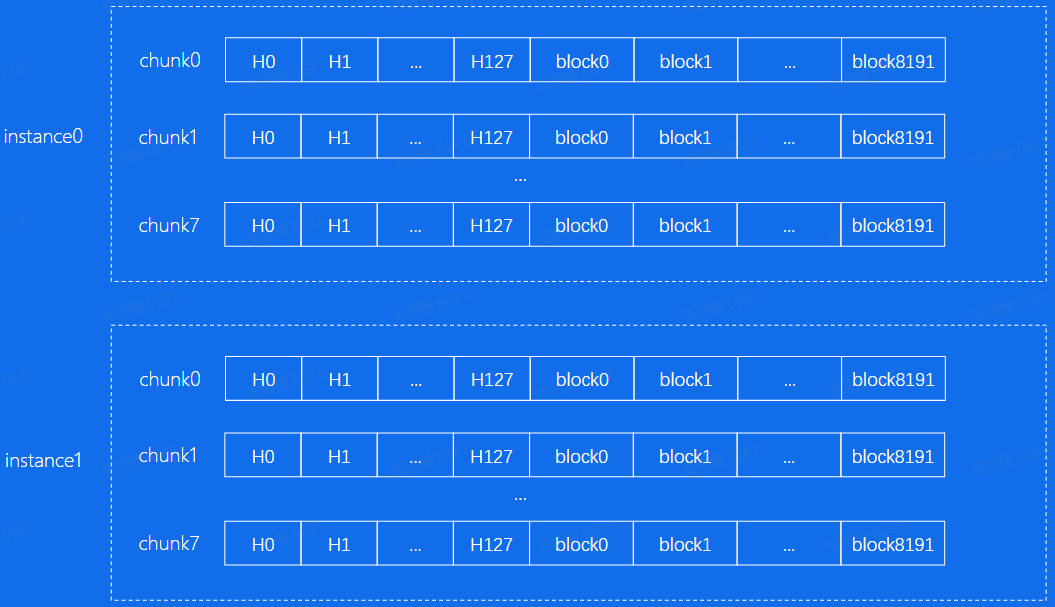
MySQL中每个chunk的大小一般为128M, 每个block对应一个page, 一个chunk 下面有8192个block。这样可以避免内存碎片化。
分成多个instance,可以有效避免并发冲突。
Page id % instance num得到它属于哪个instance
HashMap:page寻址
LRU:内存替换策略
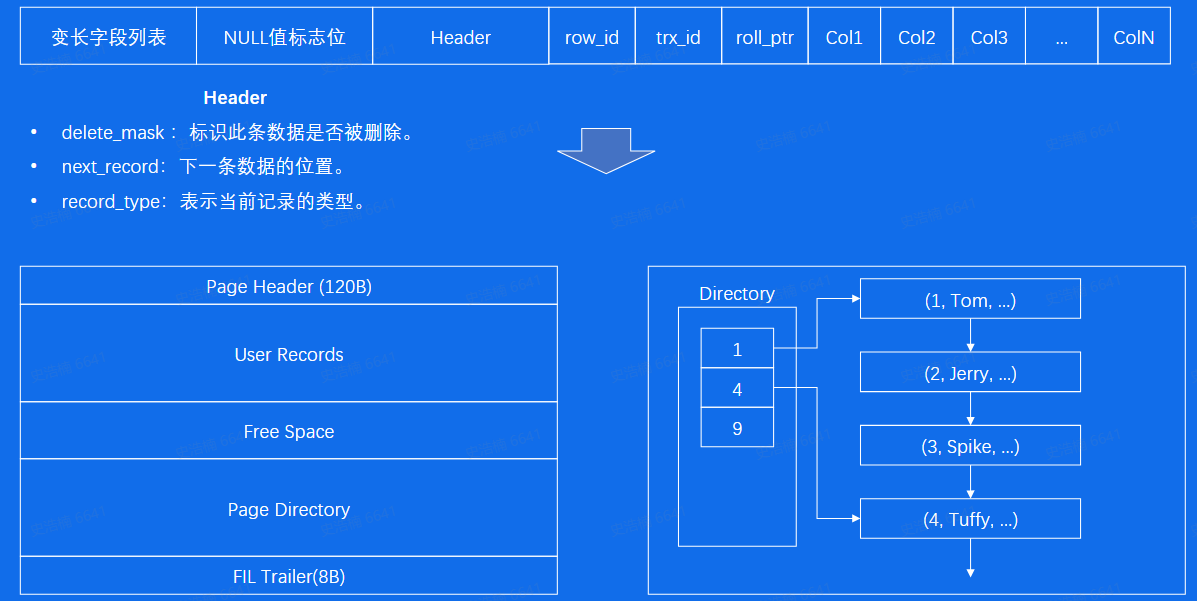
Page
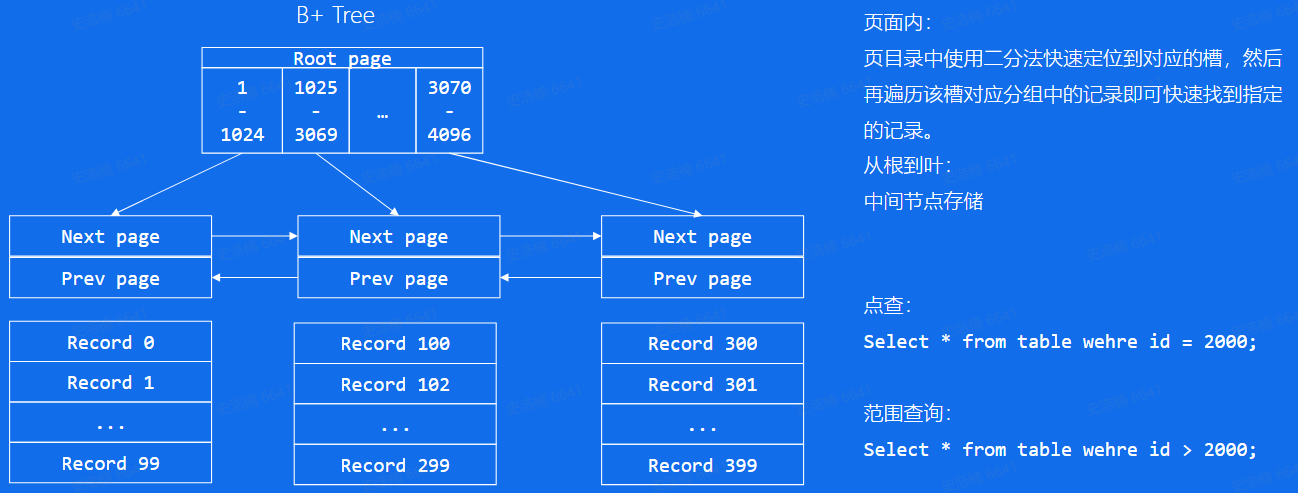
B+ Tree:构建索引
叶子节点通过双向链表连接
- 点查:从根到叶查到数据
- 范围查询:根据叶子的链表继续遍历叶子节点查询
事务引擎
原子性:如果事务执行失败需要回退,通过undo log记录数据回退的操作
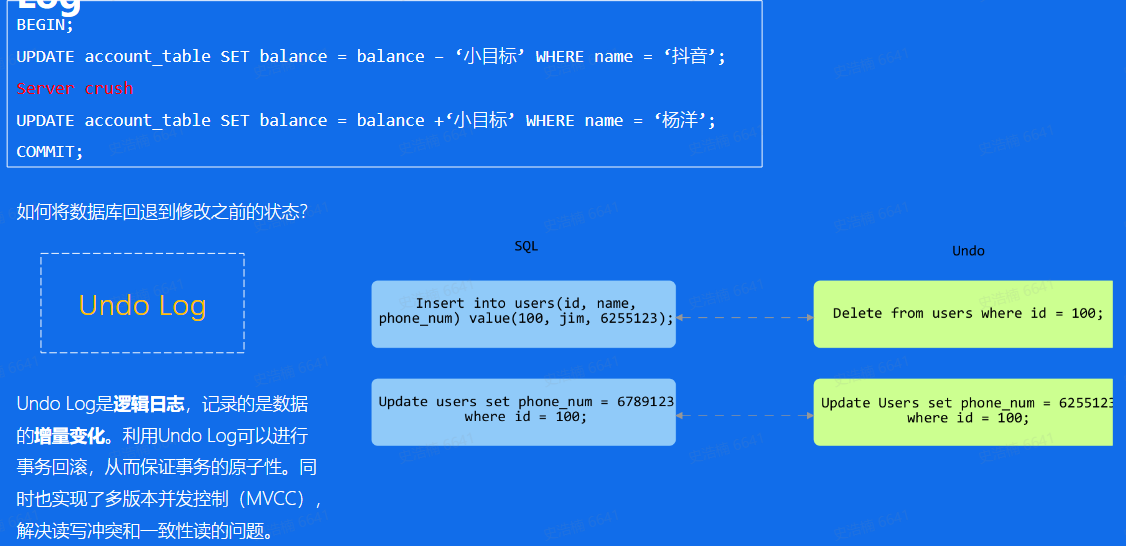
一致性:主要在业务层实现
隔离性:通过加锁实现
读读:共享锁,可以同时读
写写:排他锁,一个人写另一个人就不能再写

读写:读写互不阻塞,MVCC机制,为数据创建多个版本来支持多个事务同时读取和修改数据库。
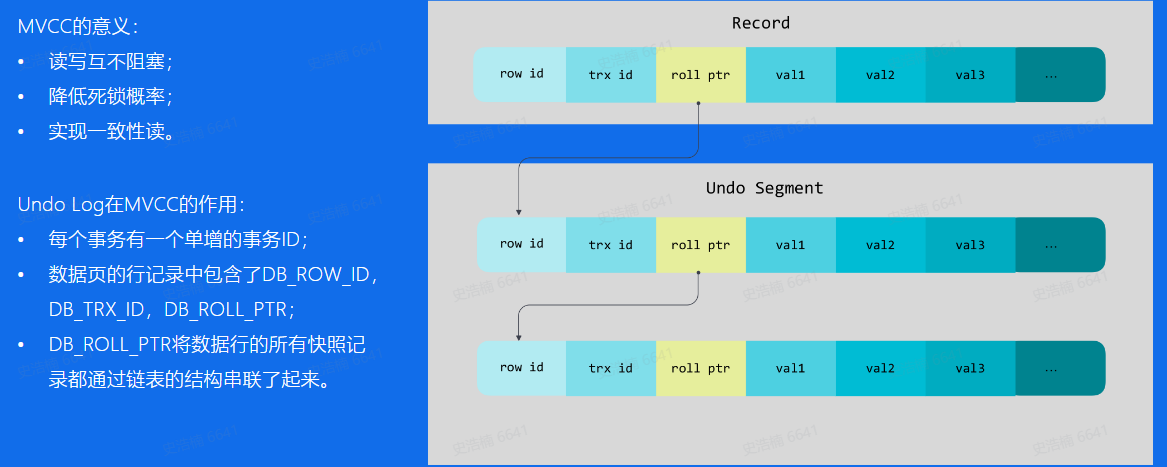
持久性
随机IO:随机访问磁盘效率较低
写放大:数据的最小管理单元是页面16(KB),写数据可能只修改几个字节,但是要占用整个页面
WAL:修改并不直接写入到数据库文件中,而是写入到另外一个称为WAL的文件中; 如果事务失败,WAL中的记录会被忽略,撤销修改; 如果事务成功,它将在随后的某个时间被写回到数据库文件中,提交修改。
优点:只记录增量变化,没有写放大;Append only,没有随机IO

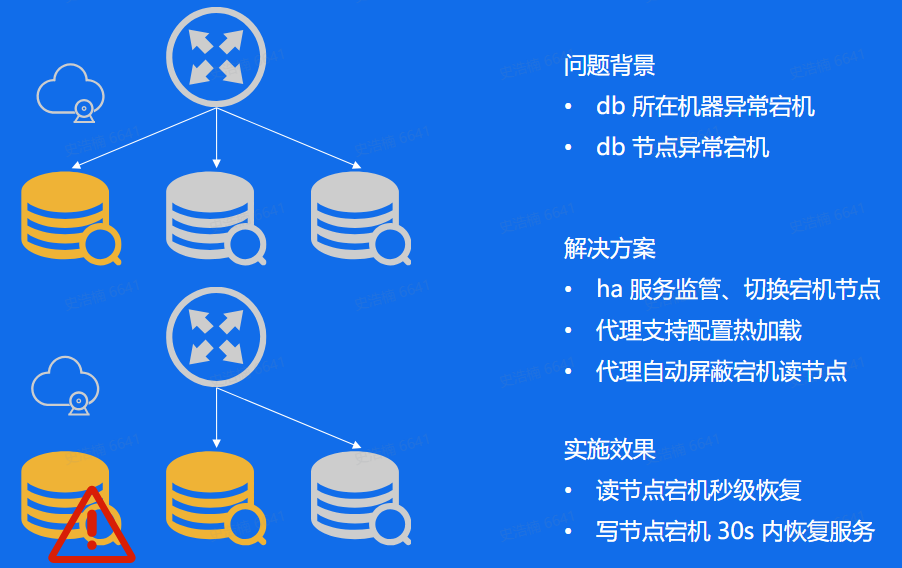
企业实践
流量大、流量突增、稳定性

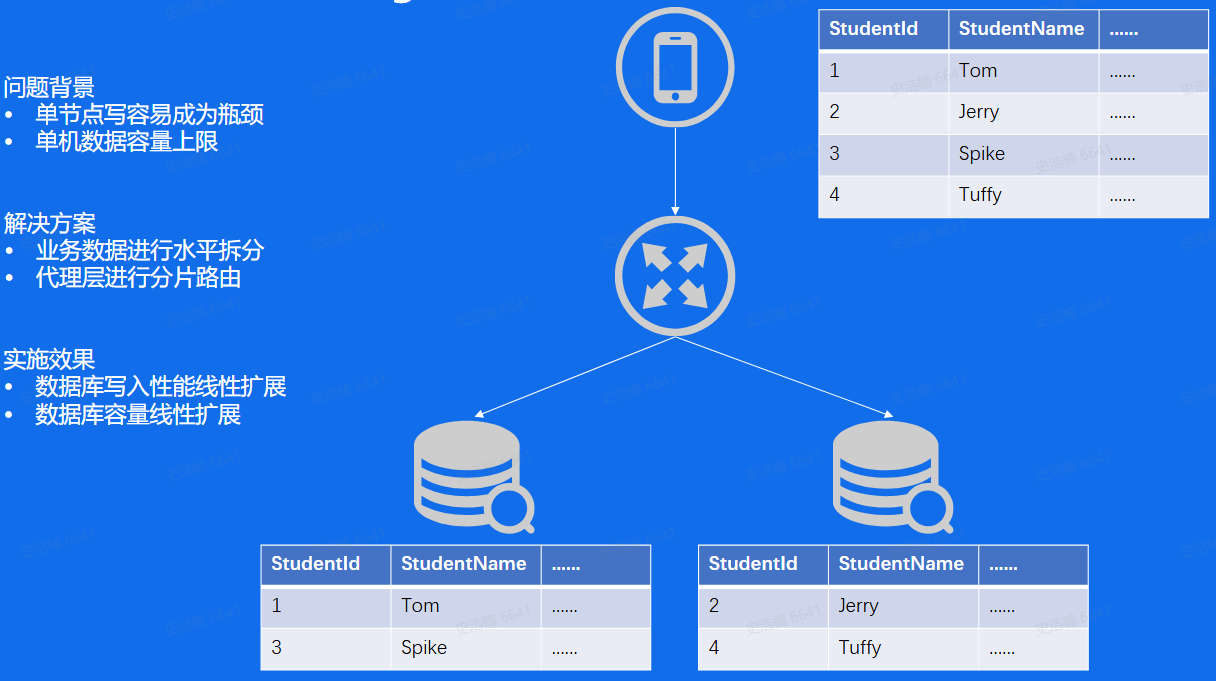
大流量
Sharding:将数据水平拆分,分给多个服务器存储
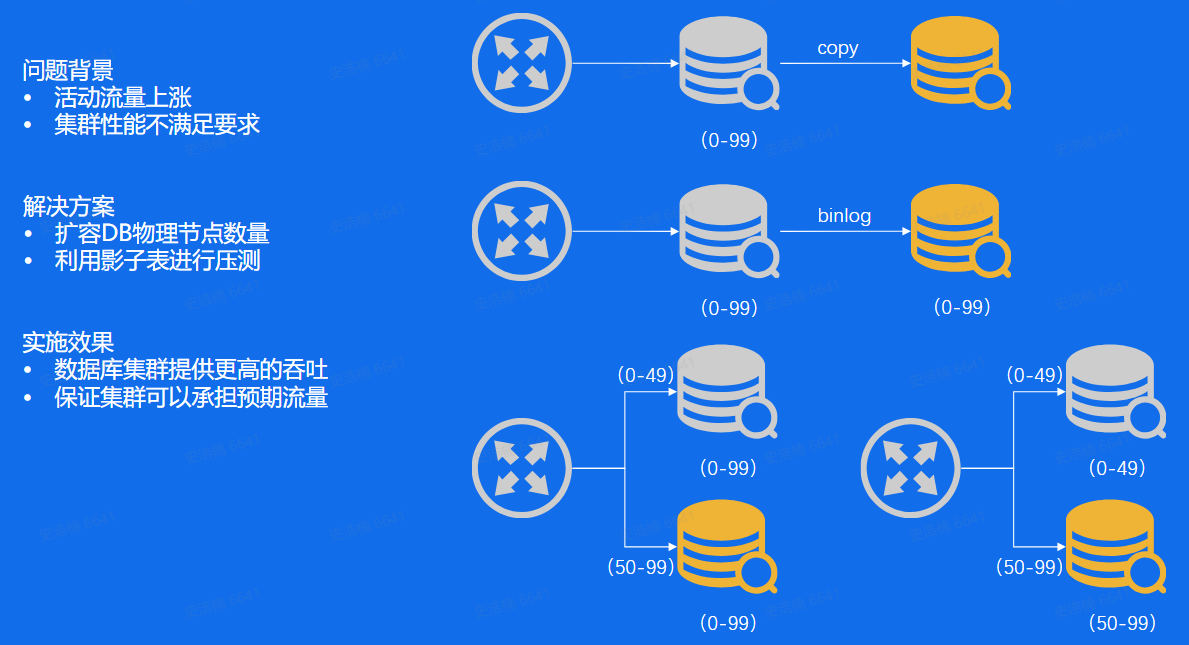
流量突增
扩容
代理连接池

稳定性&可靠性
3AZ高可用
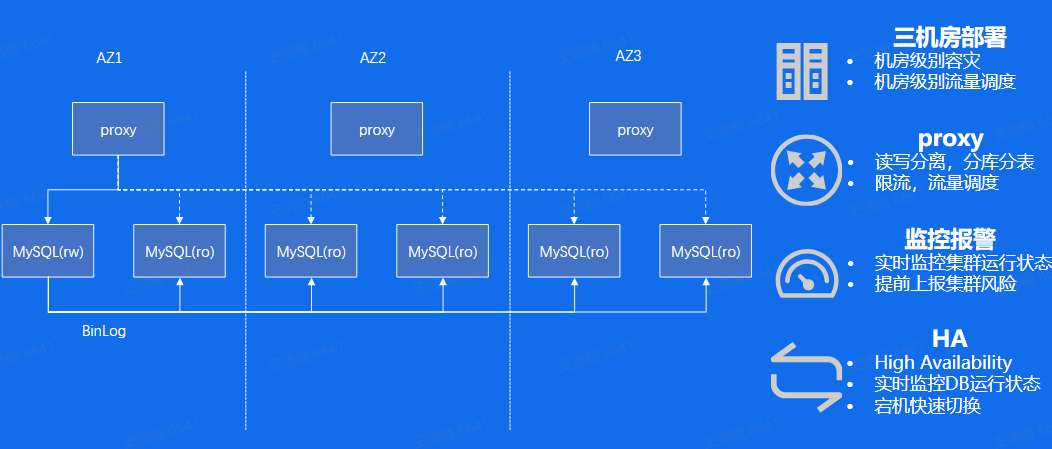
HA管理
总结
对象存储
需求
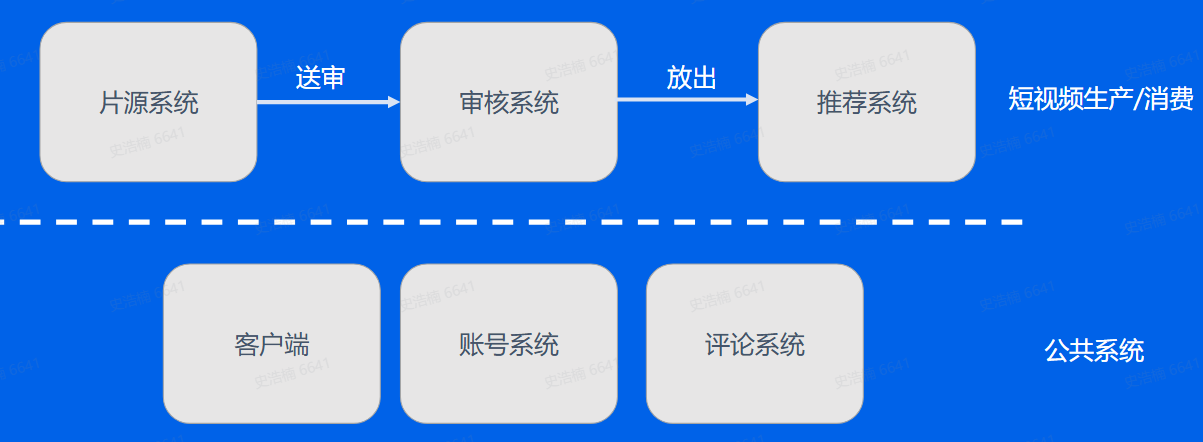
短视频架构:
存储需求:
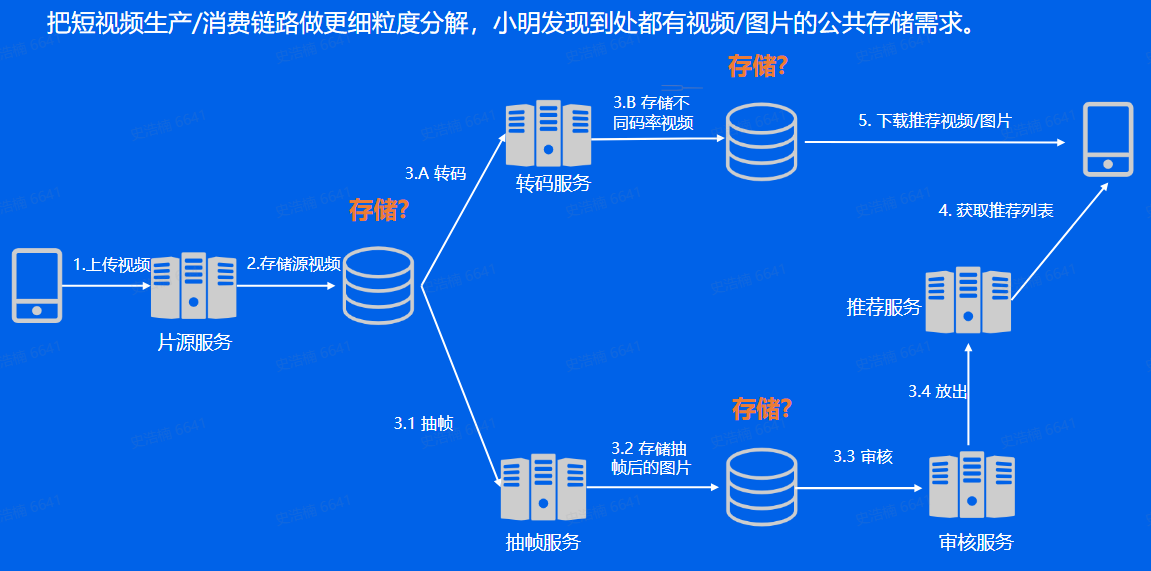
存储量:

要求:
- 易用:好的存储能够解放业务,让业务专注于业务逻辑开发
- 海量:从前面分析,这个存储系统一定要能够存储如此大的海量
- 便宜:这么大的存储量,越便宜就越能省下宝贵的经费
为什么需要对象存储
存储系统的分类:
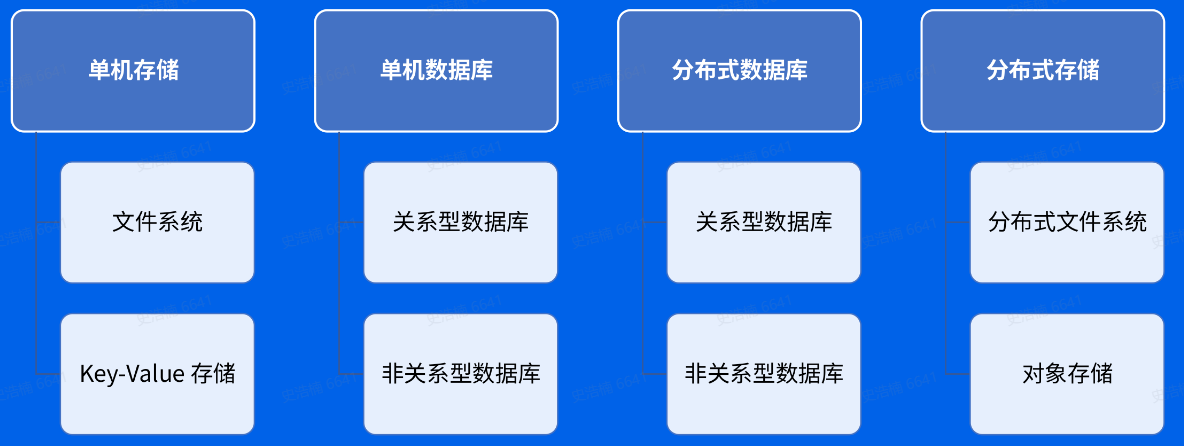
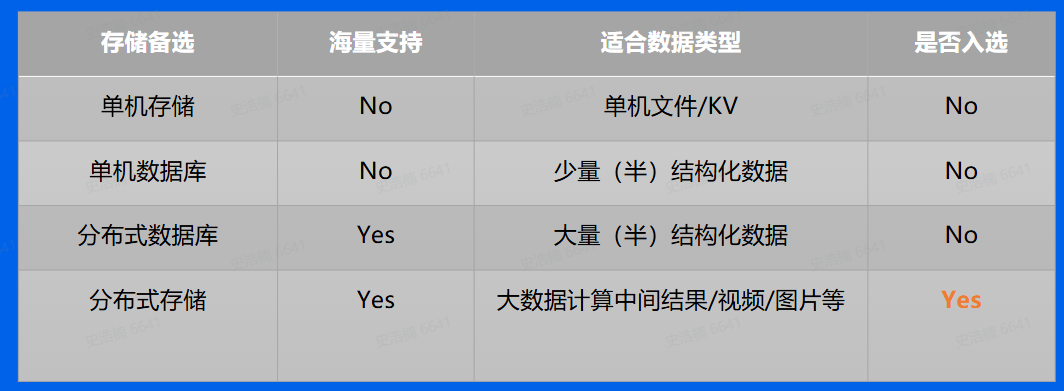
分布式数据库适合存储大量结构化数据,例如身份证号
分布式存储
包括分布式文件系统和对象存储
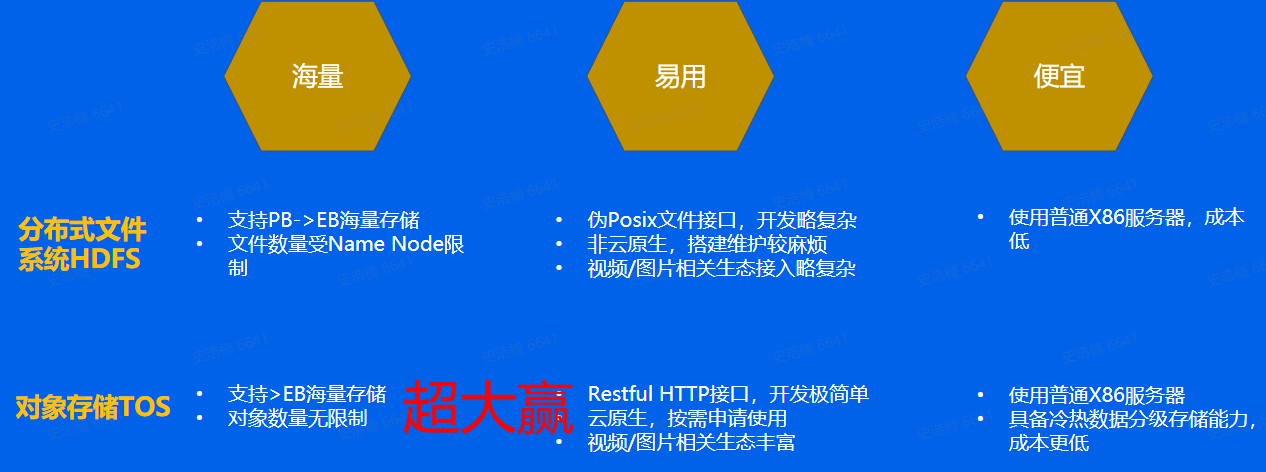
适用场景
静态不变

对象存储怎么使用
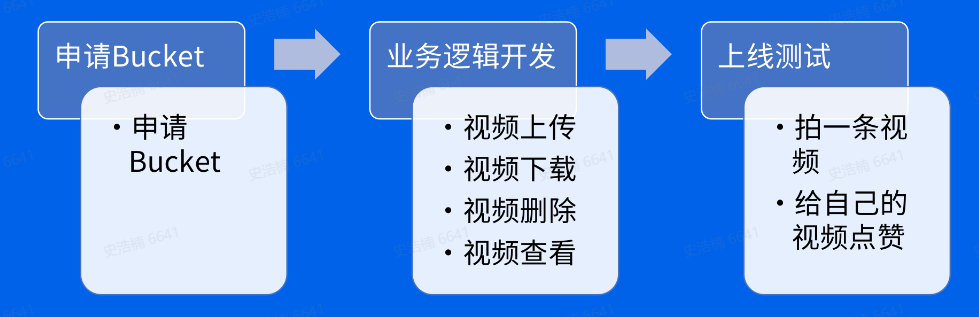
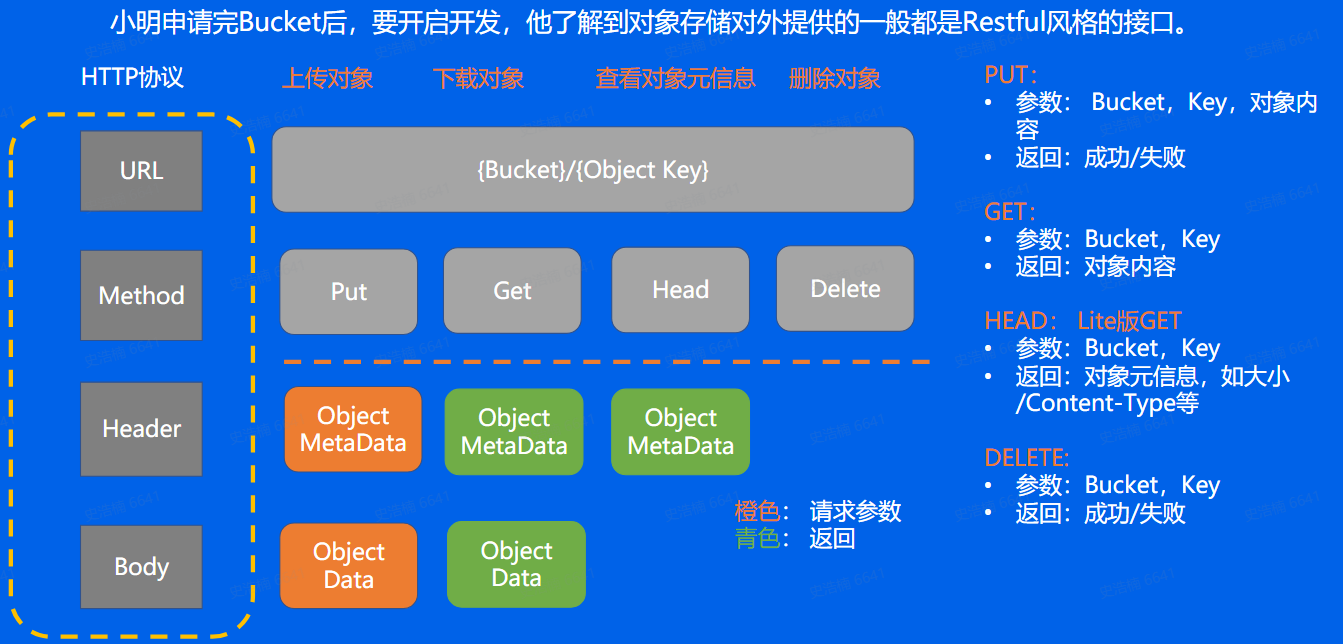
Restful接口
通过restful接口直接操作对象存储
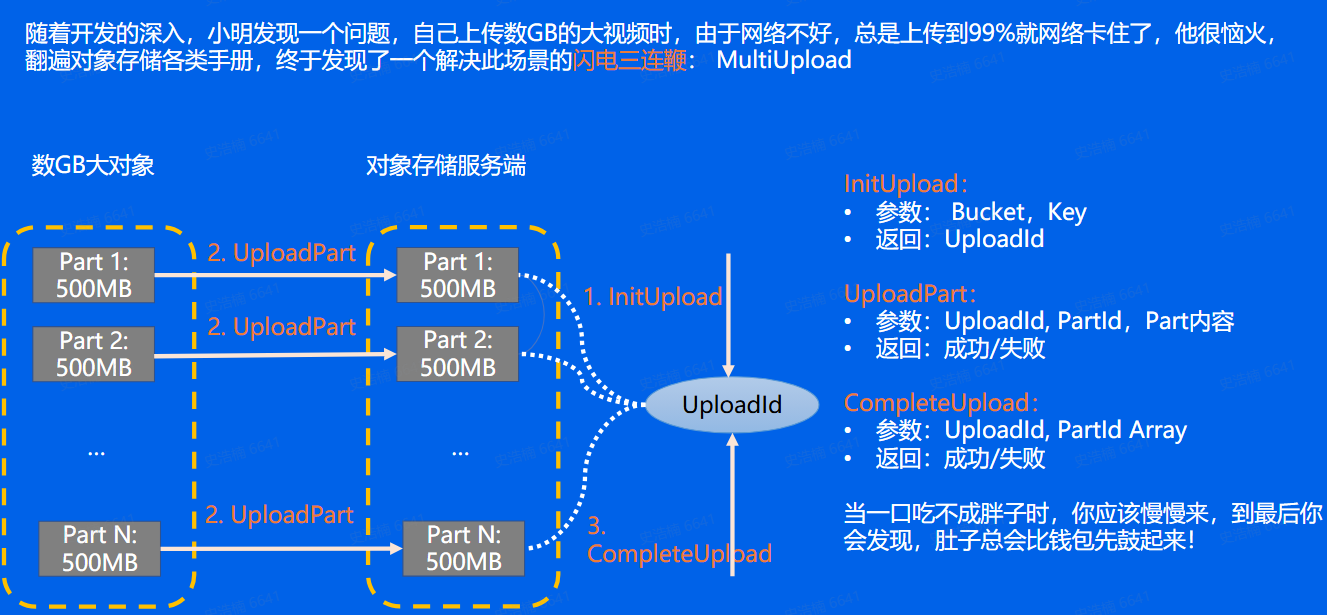
MultiUpload接口
大文件上传
ListPrefix接口
分页列举

总结


