Go语言基础知识2——内建容器
点击阅读更多查看文章内容
一、数组
数组定义
var arr [5]int:变量个数在前,变量类型在后
1 | var arr1 [5]int |
range关键字
1 | //通过range关键字可以同时获得索引及其对应元素 |
数组是值传递
[10]int 和 [20]int 是不同类型
调用func f(arr [10]int)会拷贝数组 (其他大部分语言传数组都是引用传递),
通过指针可以修改数组的值
1 | //通过指针可以修改数组的值 |
Go语言中一般不直接使用数组
二、Slice(切片)
Slice区间前闭后开
arr[2:6]、arr[:6]、arr[2:]、arr[:]都是切片
1 | func main() { |
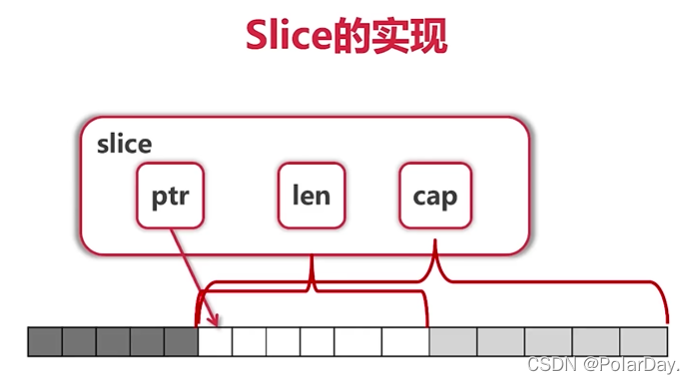
Slice本身没有数据,是对底层array的一个view
1 | arr := [...]int{0,1,2,3,4,5,6,7} |
Reslice
对slice再求slice
1 | arr := [...]int{0, 1, 2, 3, 4, 5, 6, 7} |
Slice的扩展
在以下示例中,s1为[2,3,4,5],如果直接取s1[4]会产生越界错误
使用s2再取s1的切片s1[3:5],则不会报错
1 | arr := [...]int{0, 1, 2, 3, 4, 5, 6, 7} |
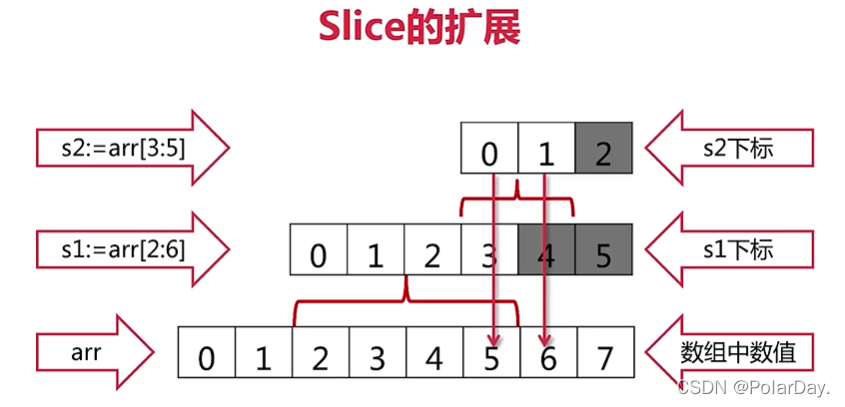
slice可以向后扩展,不可以向前扩展
s[i]不能超过len(s),向后扩展可以超过len(s)不可以超过cap(s)
1 | func main() { |
Slice的操作
向Slice添加元素
1 | func main() { |
切片在添加元素时如果超越cap,那么就不再是对原数组的view,系统会重新分配更大的底层数组
由于值传递的关系,在append时slice的len和cap都有可能改变,必须接受append的返回值 s=append(s,val)
创建Slice
1 | var s []int //Zero value for slice is nil; len = 0; cap = 0 |
copy
1 | //只copy数值 |
delete
删除元素没有内建函数
1 | //删除下标为3的元素 |
三、Map
map定义:map[Key]Value{},方括号中是key的类型,后面跟value的类型,大括号中加初始化的值
复合map:map[K1]map[K2]V,外层map的key为K1,value为map[K2]V
创建
1 | m := map[string]string{ |
遍历
使用range遍历
使用len获得元素个数
1 | //遍历,Map使用哈希表元素无序,每次输出的顺序都不同 |
取元素,判断是否存在
1 | //取元素,判断元素是否存在,若存在ok为true,否则为false |
删除元素
1
delete(m,"name")
1 | delete(m,"name") |
map中的key
map使用哈希表,key必须可以比较相等
除了slice,map,function的内建类型都可以作为key
struct类型不包含上述字段,也可作为key
四、字符串
字符串的实现
range []byte(s):使用[]byte获得字节(底层),字符串采用utf-8编码,英文一字节,中文三字节,直接输出s[idx]获得的是字符串对应位置的字节
range s:获得的是字符的Unicode编码
字符串的不同输出形式
| 字符串 | Y | e | s | 我 | 爱 | 慕 | 课 | 网 | ! |
|---|---|---|---|---|---|---|---|---|---|
| UTF-8(range []byte(s)) | 59 | 65 | 73 | E6 88 91 | E7 88 B1 | E6 85 95 | E8 AF BE | E7 BD 91 | 21 |
| Unicode(range s) | 0,59 | 1,65 | 2,73 | 3,6211 | 6,7231 | 9,6155 | 12,8BFE | 15,7F51 | 18,21 |
| range []rune(s) | 0,59 | 1,65 | 2,73 | 3,6211 | 4,7231 | 5,6155 | 6,8BFE | 7,7F51 | 8,21 |
Ps,后两行为:下标,字符;
即range s中每个中文字符占三个长度,因为字符串底层是由字节存储的,每个中文字符占三个字节,所以占三个长度
[]rune(s)中每个中文字符占一个长度,一个rune类型占四个字节,所以一个rune可以存储一个字符,
1 | s := "Yes我爱慕课网!" |
len:返回字节长度
utf8.RuneCountInString:返回字符个数
1 | fmt.Println(len(s))//19 |
使用utf8.DecodeRune解码
func DecodeRune(p []byte) (r rune, size int) {}:
输入为UTF-8编码的字节,输出为rune以及字符的所占的字节数,使用%c获得字符,汉字每三个字节进行解码
1 | bytes:=[]byte(s) |
顶层使用:将s转为[]rune下标从0递增
[]rune转换并不是对内存的重新理解,而是会将字节进行解码,将转换后的字符存放在一个新开的rune slice里面
1 | for i,ch:=range []rune(s){ //ch is a rune |
字符串的有关操作
字符串的有关操作都在strings包中
1 | //字符串分隔、拼接 |
Go语言基础知识2——内建容器

